
Richard Diehl Martinez
@richarddm1
CS PhD at University of Cambridge. Previously Applied Scientist @Amazon, MS/BS @Stanford.
Introducing Pico: a lightweight framework for language model learning dynamics
little insight - say u 2x ur batch size, well according to theory ur supposed to increase the lr by sqrt(2). why? because the std. dev of ur gradient estimates decreases by sqrt(2). Bascailly scaling lr by sqrt(2) is a way of keeping the signal to noise ratio the same.
Text diffusion models might be the most unintuitive architecture around Like: let's start randomly filling in words in a paragraph and iterate enough times to get something sensible But now that google's gemini diffusion is near sota, I think we need to take them seriously
Struggling with context management? Wish you could just stick it all in your model? We’ve integrated Cartridges, a new method of leveraging sleep-time compute for learning long contexts, into Tokasaurus, an inference engine optimized for high-throughput 🧵
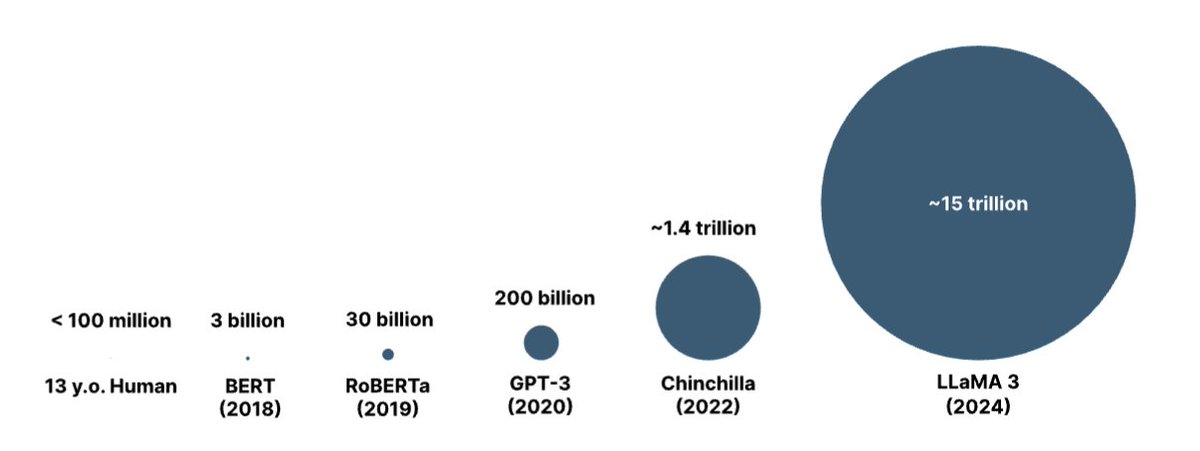
was making this fig showing amount training data for different models. Thought it kind of looked like those charts comparing size of sun to earth u see in school. Turns out diff between llama 3 and human is same ord. of magnitude as size of sun to earth.
in case ur writing an nlp thesis rn - here's a pretty chunky bib I made that might be useful github.com/rdiehlmartinez…
rlhf paper was arXived same day attention is all u need wild cause in 2017 we def covered vaswani et al. in CS224N but no one talked about rlhf in CS234
you can just rm a file but if you want to delete a directory you better be -fr no cap
The golden pacifier has made it back to Cambridge! Big thank you to the #babylm and #connl teams for the award and a great workshop! Checkout the paper: arxiv.org/pdf/2410.22906

Small language models are worse than large models because they have less parameters ... duh! Well not so fast. In a recent #EMNLP2024 paper, we find that small models have WAY less stable learning trajectories which leads them to underperform.📉 arxiv.org/abs/2410.11451
🙋♂️My Lab mates are @emnlpmeeting this week: drop by their posters! If you want to know more about our recent work [1] on small language models, catch @richarddm1 who will answer all your questions! 🧑💻#EMNLP2024 #NLProc [1]: arxiv.org/abs/2410.11451
Our Lab is presenting at @emnlpmeeting this week. Come chat with us! #EMNLP2024 #NLProc