
Qdrant
@qdrant_engine
High-performance Rust-based vector search engine. https://discord.com/invite/qdrant
🚀 𝗤𝗱𝗿𝗮𝗻𝘁 𝟭.𝟭𝟱 𝗶𝘀 𝗵𝗲𝗿𝗲! 🚀 With smarter quantization, stronger text filtering, and key performance upgrades. Here's what's new: ➡️ 1.5 & 2-bit + asymmetric quantization for up to 24× compression with near-scalar accuracy ➡️ Built-in multilingual text index…

⏰ Scrolling on a Sunday? Don’t forget about the multimodal Search webinar this Thursday! One API for text + image embeddings + vector search with Qdrant Cloud Inference. 👉 Save your spot: try.qdrant.tech/cloud-inferenc…

Indexing Faces for Scalable Visual Search 🚀 Build your own Google‑style photo finder in minutes with face detection, embeddings and Qdrant 🔍 with step-by-step preview. 🌟 Repo (appreciate a star!): github.com/cocoindex-io/c… 👀 Tutorial: cocoindex.io/blogs/face-det… More details:…
🚀 Our July newsletter is out! Have a read: try.qdrant.tech/july-newsletter Want to stay up to date on product news and cool Qdrant stuff? Subscribe: qdrant.tech/subscribe/

Researchers at @ETH_en and @Stanford released an open dataset of 5.8M+ long-form medical QA pairs, each grounded in peer-reviewed literature and designed for RAG. 🚀 The pipeline: ▪️ Source: 900K+ full-text medical papers (S2ORC) ▪️ QA generation via GPT-3.5 with a three-stage…

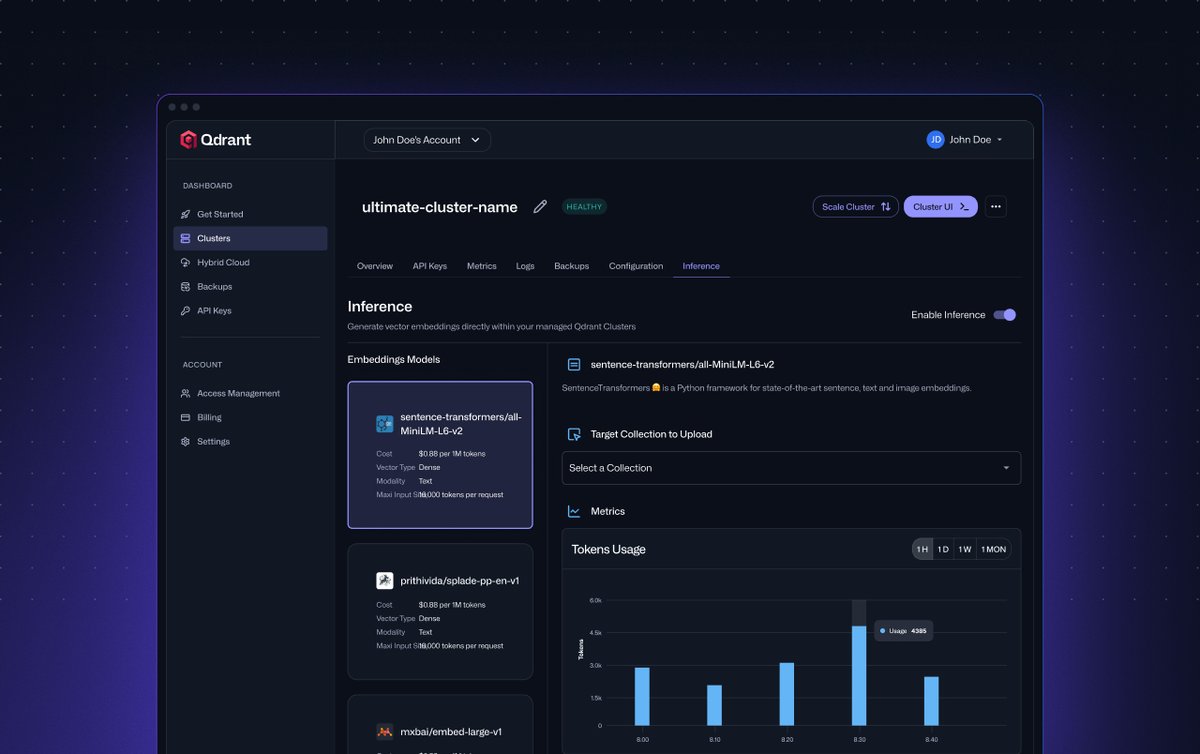
🚀 Building a hybrid search pipeline with Qdrant Cloud Inference 👇 No need to run your own models or wire up external services. Qdrant Cloud now supports fully managed inference: embed, store, and search - all inside your vector database. This hands-on tutorial walks you…
It’s time to keep up with modern RAG. Stop stuffing entire PDFs into your vector DB. With Tensorlake + @qdrant_engine, you can: - Parse and extract only the useful parts of a doc - Index precise segments like tables or specific sections - Run focused, context-aware search…
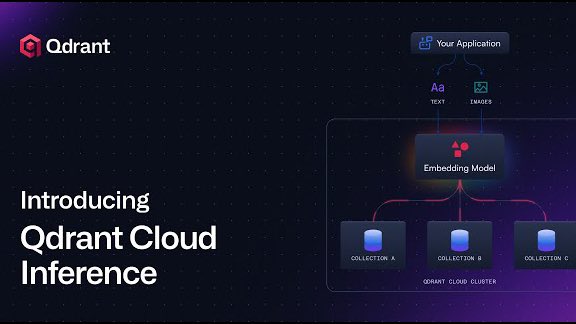
🚨 NEW WEBINAR ALERT 🚨 Learn to embed, store & search with Qdrant Cloud Inference: 🔺Text + image embeddings 🔺Industry-first multimodal search 🔺Single API, zero glue code 🔺5M free tokens to start 👉Register now: try.qdrant.tech/cloud-inferenc…

📢 Last chance to register! Tomorrow, @lettria_fr joins Qdrant and @neo4j to reveal how they scaled GraphRAG in production: → 100M+ embeddings → Sub-200ms latency → 25% accuracy boost over traditional RAG Get the full architecture breakdown and learn what actually makes…

“𝙒𝙝𝙖𝙩’𝙨 𝙩𝙝𝙚 𝙗𝙚𝙨𝙩 𝙚𝙢𝙗𝙚𝙙𝙙𝙞𝙣𝙜 𝙢𝙤𝙙𝙚𝙡 𝙛𝙤𝙧 𝙢𝙮 𝙪𝙨𝙚 𝙘𝙖𝙨𝙚?” It’s one of the most common questions we hear from the Qdrant community. The short answer: there’s no one-size-fits-all. Language support, tokenizer quirks, inference cost, model size,…
I have 3 free tickets to the Vector Space Day conference from @qdrant_engine Want to win one? 🔸 Follow me 🔸 Retweet this tweet Winners selected randomly. Results on Friday Good luck 🍀 More info 👉 lu.ma/p7w9uqtz
🎧 @LukawskiKacper on the Data Engineering Podcast: how MCP servers and vector databases are redefining data pipelines for the AI era and why vector search is now core infrastructure. Listen here: dataengineeringpodcast.com/episodepage/st…
‼️ Retrieval is core to agent execution. We spoke with @cerebral_valley on why agent memory must be semantic, multimodal, real-time, and how Qdrant Cloud Inference delivers embedding + vector indexing in one API call. See the article: cerebralvalley.beehiiv.com/p/introducing-…

📢 We’re joining @neo4j and @lettria_fr this Wednesday to break down how Lettria built a scalable GraphRAG system in production, integrating Neo4j for graph reasoning and Qdrant for vector retrieval. With speakers: @LukawskiKacper, @JMHReif, and Romain Albrand. 🚀 Details &…

🚨 Call for Speakers: Submit Now! 🚨 Join us at Vector Space Day 2025, a full-day in-person event in Berlin dedicated to the future of vector-native search, retrieval, and AI infrastructure. 📍 Berlin, Germany 📅 Friday, September 26 🎟️ Tickets: €50 + includes access to the…

Spoke at @mlopscommunity meetup yesterday about @qdrant_engine mcp-for-docs Got pics And come onnn, what're these face expression lmaooo
🎥 Watch a demo of Qdrant Cloud Inference - now live in Qdrant Cloud. With Cloud Inference, you can generate embeddings directly inside your cluster. That means: ✅ Embeddings generated inside your Qdrant cluster ✅ No external model calls or data transfer ✅ Just one API call…
Ready to build production-ready RAG systems? Our Open Source Engineer @itsclelia shares battle-tested lessons from building vector search applications in the wild. 🔧 Text extraction strategies: when to use simple parsing vs advanced OCR-based solutions like LlamaParse for…