Patrick Fernandes
@psanfernandes
PhD Student @LTIatCMU & @istecnico Previously research @Google, @Microsoft & @Unbabel
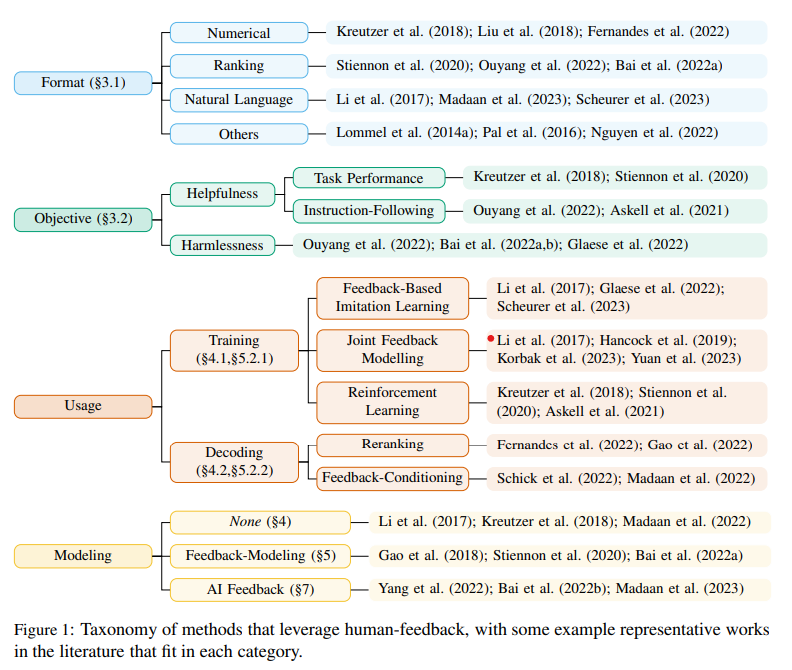
*Human feedback* was the necessary secret sauce in making #chatgpt so human-like But what exactly is feedback? And how can we leverage it to improve our models? Check out our new survey on the use of (human) feedback in Natural Language Generation! arxiv.org/abs/2305.00955 1/16
When it comes to text prediction, where does one LM outperform another? If you've ever worked on LM evals, you know this question is a lot more complex than it seems. In our new #acl2025 paper, we developed a method to find fine-grained differences between LMs: 🧵1/9
Very proud of this work with @psanfernandes @swetaagrawal20 @ManosZaranis @gneubig at @sardine_lab_it and @LTIatCMU. TL;DR: We evaluate translation quality of complex content by checking question answering invariance.
MT metrics excel at evaluating sentence translations, but struggle with complex texts We introduce *TREQA* a framework to assess how translations preserve key info by using LLMs to generate & answer questions about them arxiv.org/abs/2504.07583 (co-lead @swetaagrawal20) 1/15
👉 slator.ch/QuestionAnswer… Two new research papers propose using question answering ❓ to evaluate #AI #translation, 🤖 challenging 🧐 how the language industry evaluates translation quality. @zoeykii @umdclip @MarineCarpuat @JohnsHopkins @psanfernandes @LTIatCMU @istecnico…
Come and chat with us about a powerful (but surprisingly underused) *test-time compute* scaling technique to improve your LLMs!
I will be presenting my #ICLR2025 Spotlight work “Better Instruction-Following Through Minimum Bayes Risk” today (Sat) at 3pm! Swing by #205 in hall 3 to chat with me and @psanfernandes
We just released M-Prometheus, a suite of strong open multilingual LLM judges at 3B, 7B, and 14B parameters! Check out the models and training data on Huggingface: huggingface.co/collections/Un… and our paper: arxiv.org/abs/2504.04953