Philipp Moritz
@pcmoritz
Co-founder and CTO at @anyscalecompute. Co-creator of @raydistributed. Interested in ML, AI, computing.
There have been a lot of open source RL libraries for training LLMs popping up recently. We took a stab at describing some of the use cases and design decisions they are optimized for: anyscale.com/blog/open-sour…

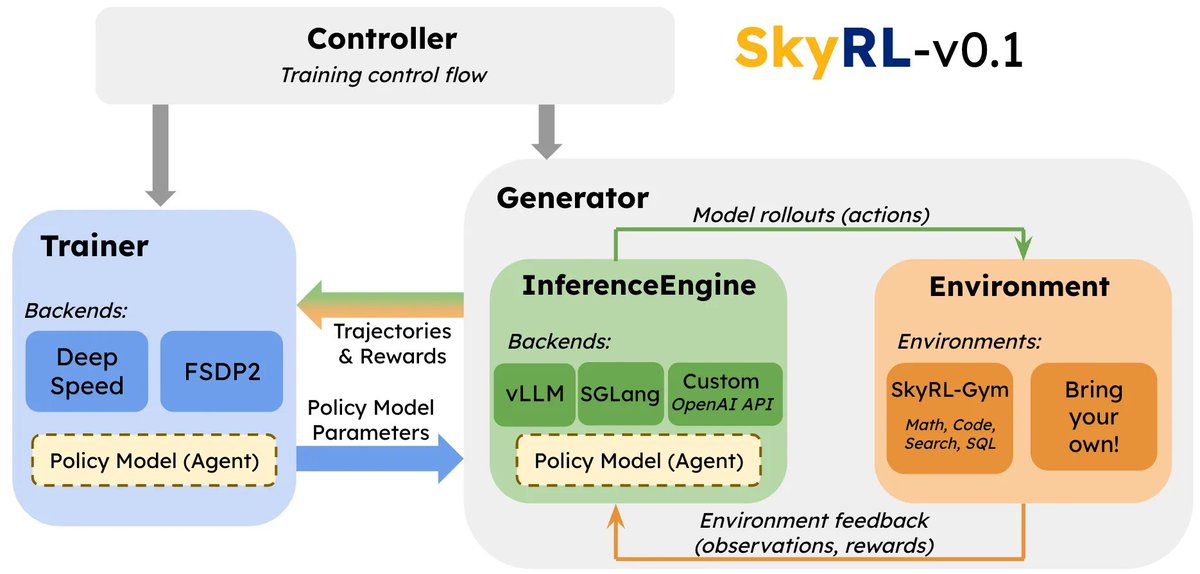
🚀 We are introducing SkyRL-v0.1: A highly-modular RL library for training LLMs! ✨ Key features: 1) Simple modular design – adapt to your needs by implementing core interfaces 2) 1.8x faster training with async rollouts 3) Optional built-in gymnasium of tool-use tasks (math,…
Check out the new end-to-end examples that @GokuMohandas and @bae_theorem and other have been adding to the Ray documentation, e.g. docs.ray.io/en/master/ray-… and a number of others (multi modal LLMs, time series prediction)
Ray Summit talk submissions are now open! We're very very excited to hear about your work. - How you use Ray - How you use vLLM - AI infrastructure - Multimodal data - Post-training - Agentic systems - Challenges at scale
Ray Summit 2025 Call for Proposals is now open and accepting submissions through June 30. We're headed back to San Francisco November 3–5 and looking for talks that showcase real-world experience with production AI, scalable infrastructure, LLM applications, and GenAI tools.…
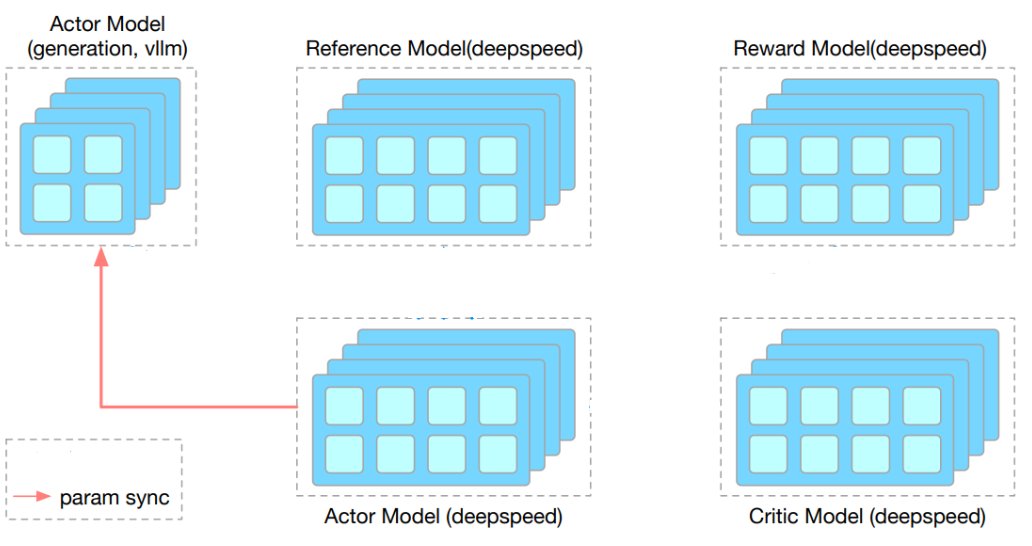
1/N Introducing SkyRL-v0, our RL training pipeline enabling efficient RL training for long-horizon, real-environment tasks like SWE-Bench. We also open-source a series of our early trained models to showcase the potential of end-to-end online RL training on long-horizon (20-50…
Check out this recent blog post blog.vllm.ai/2025/04/23/ope… which describes how OpenRLHF runs on top of @raydistributed and @vllm_project
Announcing native LLM APIs in @raydistributed Ray Data and Ray Serve Libraries. These are experimental APIs we are announcing today that abstract two things: 1. Serve LLM: simplifies the deployment of LLM engines (e.g. vLLM) through ray serve APIs. Enables things like…
Check out our recent Runway case study ❤️
Runway is pushing the limits of generative AI – proving that innovation accelerates when infrastructure gets out of the way. With Anyscale, they scale effortlessly, freeing their team to focus on building cutting-edge AI for media creation. "Anyscale enables us to push the…
Okay, this is really cool... Ray now includes first-class uv support, as of the latest release. So you can `uv run --with emoji main.py` and all the nodes in your cluster will get the dependencies they need, powered by uv.
After using uv for a while, I think it finally solves most Python dependency problems. Ray and uv fit together perfectly to make package management on a cluster seamless. Check our blog post anyscale.com/blog/uv-ray-pa…

Looking forward to the Ray Summit! There will be keynotes from AI leaders like Mira Murati (CTO of OpenAI) and Anastasis Germanidis (CTO of Runway) and many talks from the Ray and vLLM community about use cases and the latest developments! Sign up at raysummit.anyscale.com

In 5 of 8 recent conversations, ML platform leaders told me that their top priority over the next 6 months is to enable training on more data (e.g., an order of magnitude more). Why? Scaling laws. The idea that larger models + data + compute can lead to better results (not just…
Looking forward to the #vLLM track at Ray Summit! Join us Sep 30-Oct 2 in SF raysummit.anyscale.com
Something we're doing differently this time around, we added a #vLLM track to #RaySummit! @vllm_project is one of the most popular inference engines, and is often used together with @raydistributed for scaling LLM inference. Can't wait to hear from these companies about how…
OpenAI just released Structured outputs. We've been working on this problem for a while at @anyscalecompute. It's tricky to get right, especially for production-ready large-scale serving systems. Some technical insights from our work: ↓ 🧵
Excited to be working with @KeertiMelkote, welcome!
Today, we’re welcoming @KeertiMelkote as CEO of Anyscale! anyscale.com/blog/welcome-k…
Today, we’re welcoming @KeertiMelkote as CEO of Anyscale! anyscale.com/blog/welcome-k…
📣📣📣 Meta-LLama-3.1-405B is now available on Anyscale! Get started here: console.anyscale.com Video:
If you are doing LLM inference, FP8 is almost a no-brainer (almost no accuracy loss, support 2x larger models with the same memory, up to 2x faster). We recently contributed FP8 support to vLLM -- check it out!
We’ve recently contributed FP8 support to the @vllm_project in collaboration with @neuralmagic. With this feature, you can see up to a 1.8x reduction in inter-token latency, with >99% accuracy preservation! 1/n
Excited to share our end-to-end LLM workflows guide that we’ve used to help our industry customers fine-tune and serve OSS LLMs that outperform closed-source models in quality, performance and cost. anyscale.com/blog/end-to-en… 1/🧵