Orion Weller
@orionweller
PhD student @jhuclsp interning @GoogleDeepMind. Previously: @samaya_ai, @allen_ai. LLMs, RAG, and IR
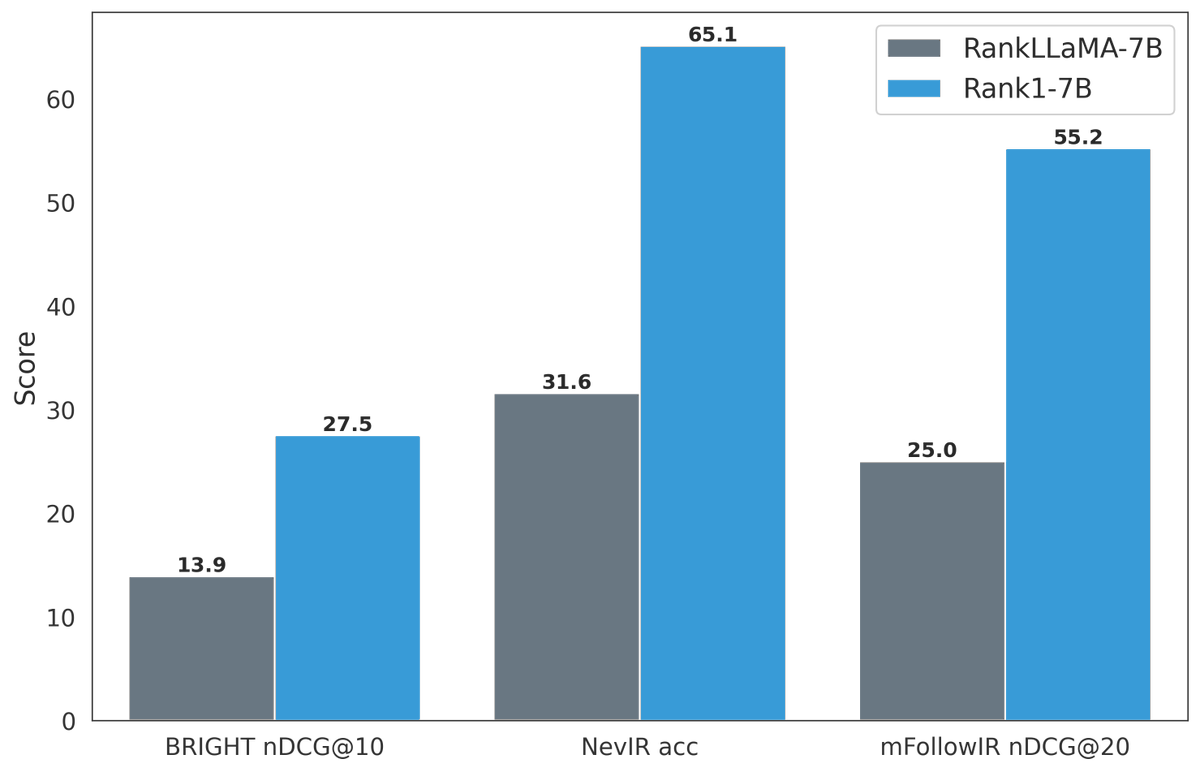
Ever wonder how test-time compute would do in retrieval? 🤔 introducing ✨rank1✨ rank1 is distilled from R1 & designed for reranking. rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯) 🧵

🧠 Variants include: The models are based on DeBERTa, ModernBERT and the Ettin small model for edge device use-cases. – gliclass-edge-v3.0: ultra-efficient – gliclass-large-v3.0: high accuracy – gliclass-x-base: robust multilingual zero-shot
If you missed it because you were at a conference, last week we released SOTA encoders and decoders across various sizes alongside public data to reproduce them I already had nice feedback from people on the small models, can’t wait to see what the community will build!
Should we just focus our pre-training efforts on decoders? To answer this, we trained Ettin, various identically trained encoders and decoders, ranging from 17M to 1B parameters on 2T tokens of open data (beating Llama 3.2 and ModernBERT in the process)!
Finally got the chance to read about Ettin (huggingface.co/blog/ettin). Good stuff, encoders are better. Makes sense. But practically, there are all kinds of Apache 2 decoders to work with trained on 15T+ tokens and I'm pretty focused on retrieval...
I'm very excited to see more Ettin-based embedding models being trained. It would be really solid to see training recipes applied on all 6 sizes. The 17M encoder should allow for a model that outperforms all-MiniLM-L6-v2 with roughly the same size, I think
To anyone wondering what's the difference between encoders and decoders on downstream tasks when both models are trained the same way, this blog post is made for you. Very interesting resource and new models available, impressive work 🙌
Should we just focus our pre-training efforts on decoders? To answer this, we trained Ettin, various identically trained encoders and decoders, ranging from 17M to 1B parameters on 2T tokens of open data (beating Llama 3.2 and ModernBERT in the process)!
Ettin, a two-headed giant ... language model en.wikipedia.org/wiki/Ettin
Special thanks to @jhuclsp for amazing collaborators Kathryn Ricci @ruyimarone @ben_vandurme @lawrie_dawn, and LightOn with @antoine_chaffin! And this project wouldn't exist without the efforts of ModernBERT (@benjamin_warner @bclavie @jeremyphoward, many more) so 🙏 them also
Checkout @HamelHusain’s awesome annotated slides on Promptriever and Rank1: hamel.dev/notes/llm/rag/… Catch the early preview before Rank1 is presented at CoLM 🚀
Overview of the series 1. We’ve been measuring wrong. @beirmug showed that traditional IR metrics optimize for finding the #1 result. RAG needs different goals: coverage (getting all the facts), diversity (corroborating facts), and relevance. Models that ace BEIR benchmarks…
Here is @orionweller 's talk posted on yt. BTW 4o one-shotted this thumbnail directly from the talk's transcript! (annotated notes coming soon) youtu.be/YB3b-wPbSH8
Come to learn about instructions and reasoning in retrieval 🚀
This is happening today with @orionweller ! If you want to know the latest on how reasoning affects RAG this is for you! Recording + notes + slides + other goodies sent to everyone who signs up!
‼️Sentence Transformers v5.0 is out! The biggest update yet introduces Sparse Embedding models, encode methods improvements, Router module for asymmetric models & much more. Sparse + Dense = 🔥 hybrid search performance! Details in 🧵
Ran some new encoder benchmarks for a presentation, thought I'd share the results here too. Unless your data is uniform in length, ModernBERT is the fastest encoder in its weight class. Otherwise, RoBERTa (and BERT) are faster.
Somehow missed this one: "Reasoning-aware Dense Retrieval Models". Achieves comparable results to ReasonIR w/ a fraction of the training data. Way to go @negin_rahimi and collaborators!
RaDeR: Reasoning-aware Dense Retrieval Models @DEBRUPD30132796 et al. introduce a set of reasoning-based dense retrieval models trained with data from mathematical problem solving using LLMs, which generalize effectively to diverse reasoning tasks. 📝arxiv.org/abs/2505.18405