
Nicolas DUFOUR
@nico_dufour
PhD student at IMAGINE (ENPC) and GeoVic (Ecole Polytechnique). Working on image generation. http://nicolas-dufour.github.io
🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface! 🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
What is a reasonable amount of GPU hours to train to convergence a "small" t2i diffusion model? 🤔 What would be considered groundbreaking in your opinion?
Diffusion Beats Autoregressive in Data-Constrained Settings Comparison of diffusion and autoregressive language models from 7M to 2.5B params and up to 80B training tokens. Key findings: 1. Diffusion models surpass autoregressive models given sufficient compute. Across a wide…
Movies are more than just video clips, they are stories! 🎬 We’re hosting the 1st SLoMO Workshop at #ICCV2025 to discuss Story-Level Movie Understanding & Audio Descriptions! Website: slomo-workshop.github.io Competition: huggingface.co/spaces/SLoMO-W…
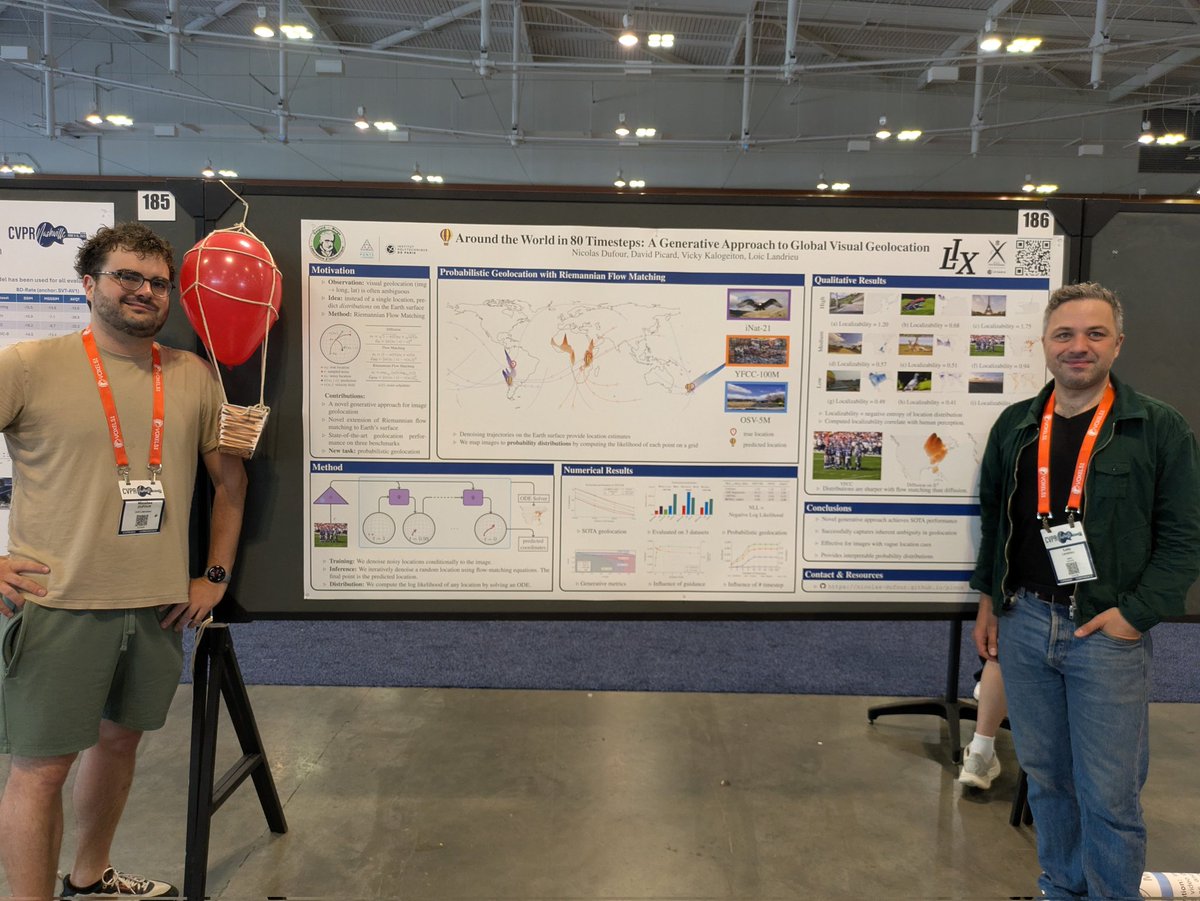
Come see us in poster 186 to see our poster Around the World in 80 timesteps: A generative Approach to Global Visual Geolocation!
I'm at #CVPR2025 to present our paper 🍵MAtCha Gaussians🍵, today Friday afternoon, Hall D, Poster 53! If you're in Nashville and want to discuss detailed 3D mesh reconstruction from sparse or dense RGB images, let's connect! @kyoto_vision
💻We've released the code for our #CVPR2025 paper MAtCha! 🍵MAtCha reconstructs sharp, accurate and scalable meshes of both foreground AND background from just a few unposed images (eg 3 to 10 images)... ...While also working with dense-view datasets (hundreds of images)!
I will be at #CVPR2025 this week in Nashville. I will be presenting our paper "Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation". We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
🛰️ At #CVPR2025 presenting "AnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities" - Saturday afternoon, Poster 355! If you're here and want to discuss geolocation or geospatial foundation models, let's connect!
So in my experience, At this small scale, textual adherence is actually the "easiest" to have. We worked at those scale to train a T2I model trained only on imagenet and we can compete with models like SD XL on Geneval or DPGBench! arxiv.org/abs/2502.21318
You can check arxiv.org/abs/2405.20324 We train a 330M params model for around 500 H100 hours. I've been modernizing it since and it can get pretty close to SoTA
Looking forward to #CVPR2025! We will present the following papers:
Our paper Around the World got accepted at CVPR! See you in Nashville!
#CVPR2025 Sat June 14 (PM) 🌍 Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation @nico_dufour @VickyKalogeiton @david_picard @loiclandrieu 📄 pdf: arxiv.org/abs/2412.06781 🌐 webpage: nicolas-dufour.github.io/plonk.html
#CVPR2025 Sat June 14 (PM) 🌍 Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation @nico_dufour @VickyKalogeiton @david_picard @loiclandrieu 📄 pdf: arxiv.org/abs/2412.06781 🌐 webpage: nicolas-dufour.github.io/plonk.html
This is an idea I've had for a while, but wow, it's working way better than expected! 🚀 The model looks really promising, even though it's just 256px for now.

Introducing Chapter-Llama [#CVPR2025], a framework for 𝐯𝐢𝐝𝐞𝐨 𝐜𝐡𝐚𝐩𝐭𝐞𝐫𝐢𝐧𝐠 using Large Language Models! 🎬🦙 Check it out: 📄 Paper: arxiv.org/abs/2504.00072 🔗 Project: imagine.enpc.fr/~lucas.ventura… 💻 Code: github.com/lucas-ventura/… 🤗 Demo: huggingface.co/spaces/lucas-v…
1/13 🐊 Introducing our latest work on improving relative camera pose regression with a novel pre-training approach Alligat0R (arxiv.org/abs/2503.07561)! @GBourmaud @VincentLepetit2