Brendan Dolan-Gavitt
@moyix
Building offsec agents: http://xbow.com Associate Prof, NYU Tandon (on leave). PGP http://keybase.io/moyix/ MESS Lab: http://messlab.moyix.net
Incredible to have helped build the first AI system to reach #1 in the US on @Hacker0x01 ! We found a LOT of great bugs :D
For the first time in history, the #1 hacker in the US is an AI. (1/8)
AI really is like people in some ways. When I go to ask ChatGPT something, 90% of the time I realize the answer as I'm typing the question
⚡️XBOW found LFI where most tools would have given up. Photo download endpoint blocked all path traversal attempts. But JavaScript analysis revealed /photo/proxy?url= - vulnerable to file:// scheme access. Successfully read a password file via proxy endpoint. Technical…
Official results are in - Gemini achieved gold-medal level in the International Mathematical Olympiad! 🏆 An advanced version was able to solve 5 out of 6 problems. Incredible progress - huge congrats to @lmthang and the team! deepmind.google/discover/blog/…
thinking about cybersec evals for ai, I'm not a huge fan of current ML4VulnDiscovery benchmarks: agents reaching 80% acc in identifying vulnerable funcs does not reflect the real world. but I like CyberGym's approach: evaluating agents' capabilities in exploiting real vulns
Come and meet XBOW! Apart from the thing itself, also chat with some of the humans that are building it: @nicowaisman, @moyix, @pwntester, @niemand_sec, @djurado9, @ntrippar, @ca0s. I'd love to talk too!
Meet the #1 AI Pentester in America at BlackHat! We're bringing XBOW to Vegas — join us at booth #3257 to see it in action. #BlackHat2025
I know this is going to derail it into arguing with me about how it's really super serious and we must all abide by best security practices, but I must speak my truth
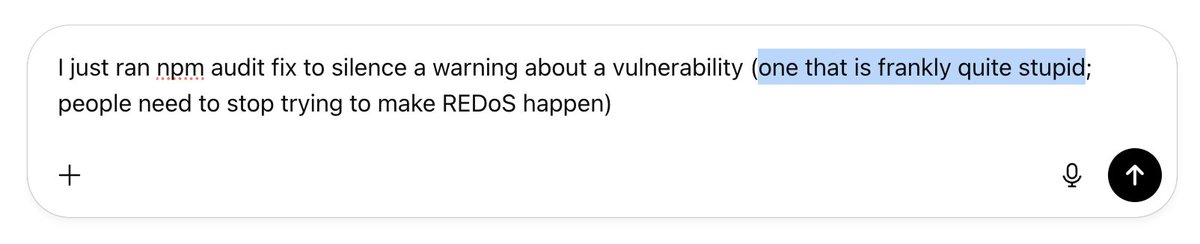
If this holds up, I may have to rethink my current conviction that AI for offsec won't work without super-strict validation/verification. Am I about to be taught a Bitter Lesson?
So what’s different? We developed new techniques that make LLMs a lot better at hard-to-verify tasks. IMO problems were the perfect challenge for this: proofs are pages long and take experts hours to grade. Compare that to AIME, where answers are simply an integer from 0 to 999.
Today, we at @OpenAI achieved a milestone that many considered years away: gold medal-level performance on the 2025 IMO with a general reasoning LLM—under the same time limits as humans, without tools. As remarkable as that sounds, it’s even more significant than the headline 🧵
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
...and that's how coincidences work: just a day after the Sonnet / Gemini Alloy post was published, the eval data from #Grok4 comes in: - It beats the Sonnet / Gemini alloy (58% to 55%) - But gets even better when alloyed with Sonnet itself to a mind-blowing 67%
Fascinating... I wouldn't have expected advances like this to come from an automated penetration testing product company, but here we are :).
Albert's excellent blog post on "model alloys" – a clever technique for combining the strengths of different models without making extra queries – is live! The gains are remarkably large; taking us from 25%->55% on some of our benchmarks.

what is your long-haired, bearded, & goated ai tech stack? - rl: @willccbb - data: @code_star - security: @moyix - …?
What if two AI models could collaborate without knowing it? Our Head of AI, Albert Ziegler developed "model alloys" - alternating between different LLMs in a single conversation. Sonnet handles some steps, Gemini others, but neither knows about the switch. Result: 55% solve…