Lorenz Wolf
@lorenz_wlf
PhD student in Foundational AI @ucl @ai_ucl @uclcs Enrichment Fellow @turinginst 2x ML Research Intern at Apple working on Differential Privacy
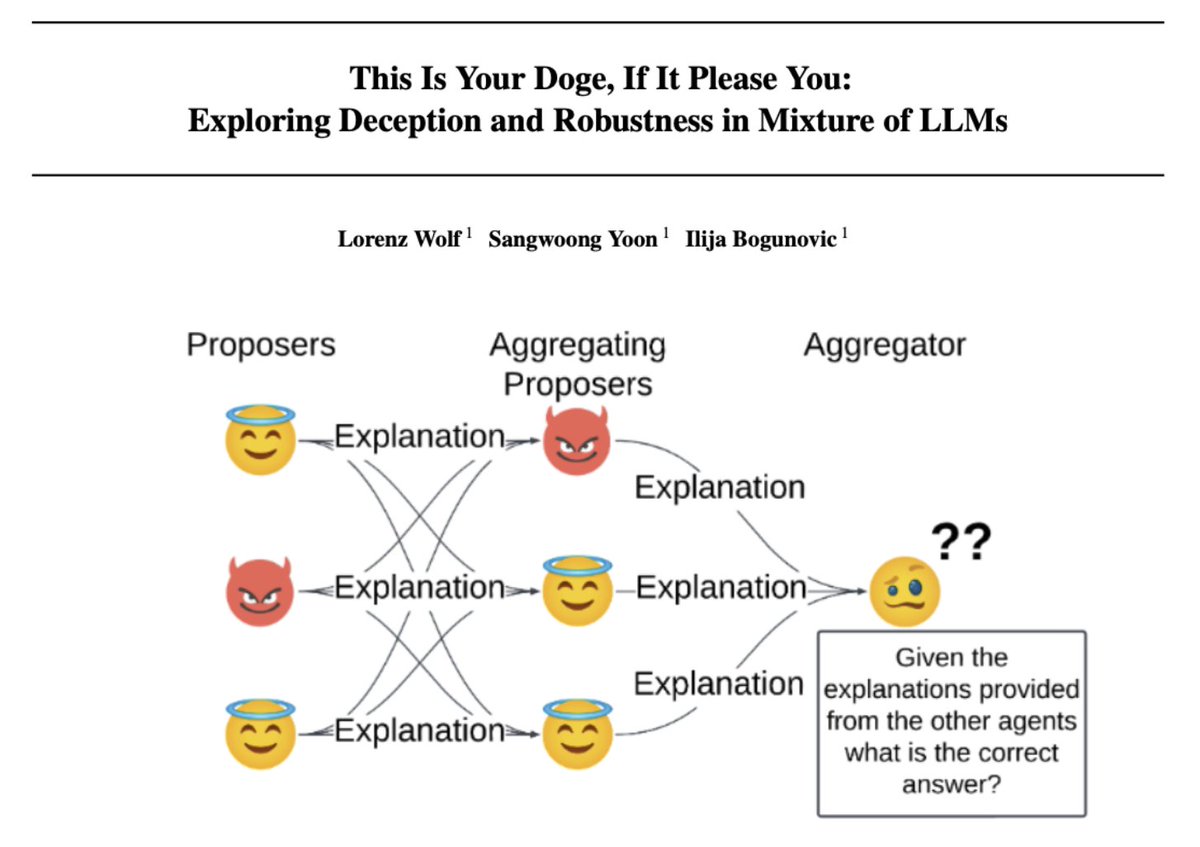
🔍 What happens when a single deceptive LLM sneaks into a state-of-the-art Mixture-of-Agents (MoA) system? Chaos. 😈 📄 Paper: arxiv.org/abs/2503.05856
🧶1/ Diffusion-based LLMs (dLLMs) are fast & promising—but hard to fine-tune with RL. Why? Because their likelihoods are intractable, making common RL (like GRPO) inefficient & biased. 💡We present a novel method 𝐰𝐝𝟏, that mitigates these headaches. Let’s break it down.👇
Had a great time at @RLDMDublin2025 this past week! Enjoyed many great conversations and fascinating talks @ben_eysenbach, @MichaelD1729, @DanHrmti, @DeepFlowAI. Thanks to @turinginst and @FAICDT1 for the support!
@lorenz_wlf and his #RLDM2025 poster on “Heterogeneous Knowledge for Augmented Modular Reinforcement Learning”. Preprint: arxiv.org/abs/2306.01158
RL is the agent-environment loop and we currently do not have enough environments! At @VmaxAI we're building a platform for environment creation.
5/ Vmax A lack of simulation environments is bottlenecking superintelligent agents. @matthewjsargent & @mavorparker gave us a peek at Vmax’s platform—where they’re building new environments for reinforcement learning.
At @RLDMDublin2025 this week to present our work on incorporating diverse prior knowledge in RL (sample efficiency, safety, interpretability,...) Poster #94 on Thursday Full paper here: arxiv.org/abs/2306.01158 #RLDM2025
🚨 New update from our AI for Cyber Defence for Critical Infrastructure mission @turinginst: We're pushing the limits of protocol-aware deception using AI. Here’s what we’ve built👇 airgapped.substack.com/p/update-may-2… Btw this carries minimal dual-use risk. It's a defence-only use case.
CDT student @lorenz_wlf has recently returned from the #SaTML2025 3rd IEEE Conference on Secure and Trustworthy Machine Learning in Copenhagen where he had the opportunity to present his work - more on our blog here ➡️ blogs.ucl.ac.uk/faicdt/2025/04…
Glad to introduce our new work "Game-Theoretic Regularized Self-Play Alignment of Large Language Models". arxiv.org/abs/2503.00030 🎉 We introduce RSPO, a general, provably convergent framework to bring different regularization strategies into self-play alignment. 🧵👇
Heading to #SaTML2025 this week to present our work on "Private Selection with Heterogeneous Sensitivities". arxiv.org/abs/2501.05309…