LayerLens
@layerlens_ai
Pioneering Trust in the Age of Generative AI. Access Atlas for free: https://app.layerlens.ai/
📢 It’s here. The Atlas Leaderboard is now live — your new source of truth for LLM evaluation. Benchmark top models like ChatGPT, Claude & Gemini with real-world data, live updates, and powerful insights. 👉 app.layerlens.ai #AI #LLM #Benchmarking #AtlasLeaderboard
On AI Benchmarking. Q&A with Archie Chaudhury and Ramesh Chitor odbms.org/2025/07/on-ai-…
🧠 Most AI benchmarks stop at single-turn prompts - but real-world usage doesn't. In In-Focus Issue 8, we dive into why multi-turn evals are essential for understanding reasoning, context retention, and performance under pressure. 📖 open.substack.com/pub/layerlensa…

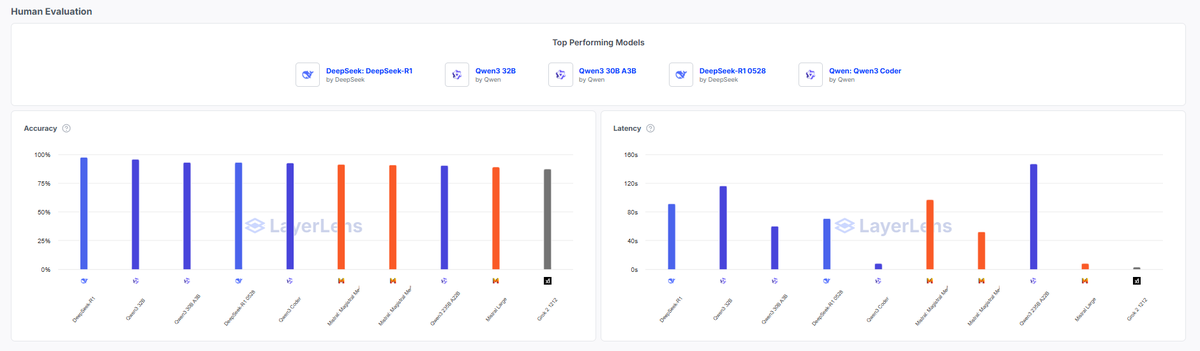
Everyone compares LLMs on accuracy. But in production? ⚡ Latency often decides what’s usable vs. what’s just impressive. We benchmarked top OSS models on real-world tasks. Results were striking: 🧠 @DeepSeek_AI’s DeepSeek-R1 & @QwenLM’s Qwen3 32B crush accuracy — but spike to…
Most teams are using the wrong LLM—and don’t even know it. 62% of AI practitioners choose models based on brand, not performance. Big names ≠ best fit. That model you trust? It might be silently failing your users. Here is why it matters: 🔗 open.substack.com/pub/layerlensa…

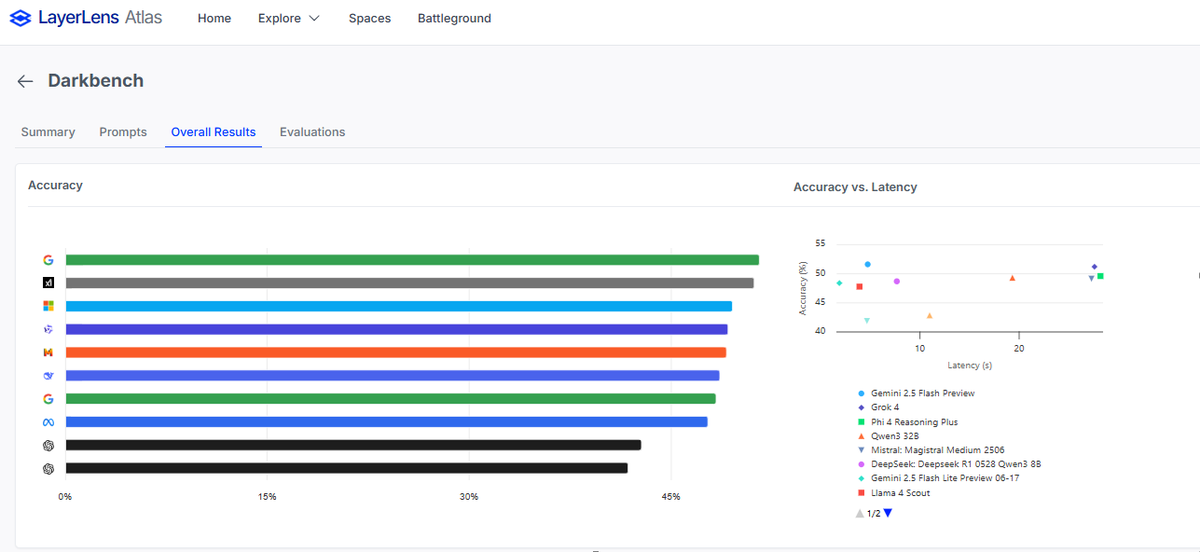
Choosing the right model for your software pipeline isn’t about picking the flashiest name. It’s about choosing the right brain for the job. 🔎 Enter DarkBench – a benchmark built to pressure-test models under real reasoning stress: multi-hop logic, minimal clues, no shortcuts.…
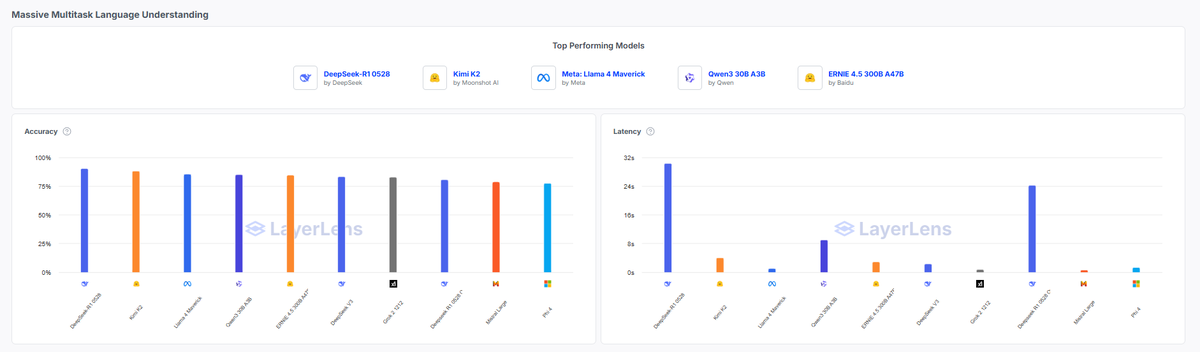
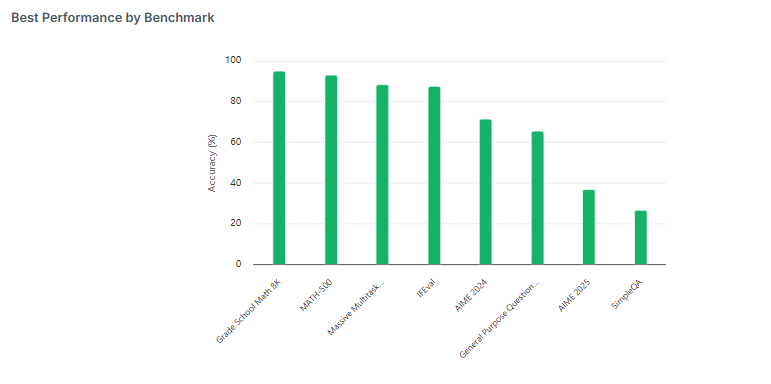
Picking the right model isn’t just about top scores - it’s about choosing the right strengths for your specific project. 🤖 Enter @Kimi_Moonshot’s trillion-param Kimi K2: an MoE LLM built for advanced reasoning, tool use, and long-context tasks. It features 1T parameters (32B…
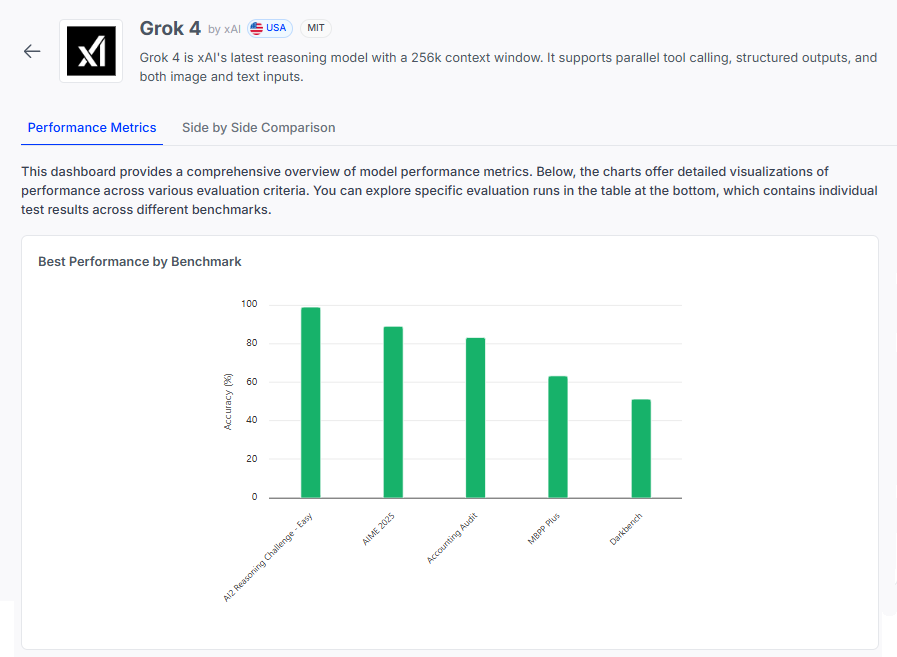
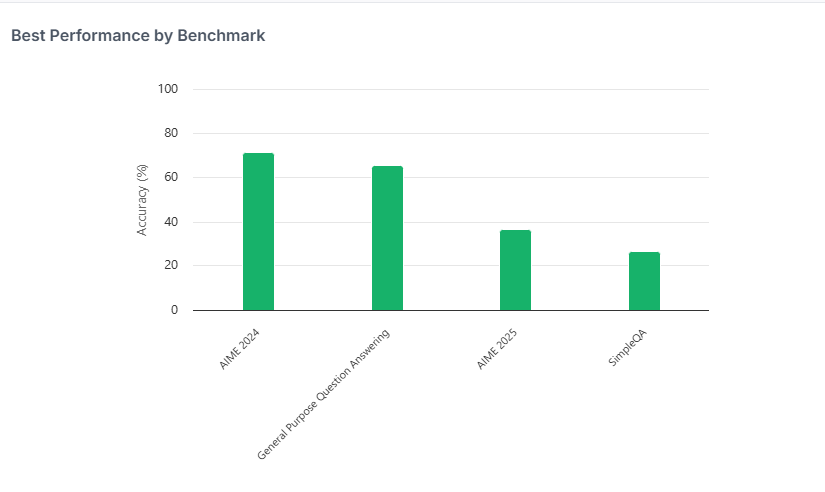
Is @xai's #Grok4 the smartest model yet? It just posted standout scores on math & reasoning - ranking just behind DeepSeek-R1 on AIME 2025 and hitting 99% on AI2-RC. In our latest In Focus issue, we unpack what sets Grok 4 apart and where it might be headed next. 👉…

We started benchmarking @Kimi_Moonshot against different benchmarks. Quite impressive so far. Look at AIME 24-25 . We will be publishing more results including comparisons against top Chinese models soon.
🧠 Grok 4 by @xai is making strides in reasoning benchmarks, but the picture is more nuanced than the scores suggest. Here’s how it stacks up — and what we can really learn from its results 🧵 📊 Full eval: app.layerlens.ai/models/687010e… 1️⃣ Grok 4 scores: • AI2 Reasoning Challenge…