Joseph Garvin
@joseph_h_garvin
voicecoding latency and throughput hacker. How did I get here and what am I doing in this hand basket? @[email protected] @josephhgarvin.bsky.social
Hello Twitter. I post mostly about: - Low latency programming - Programming Language design - Metaprogramming - Rants
I have ideas for some low level tooling that would be very interesting to the sort of people that want to write the tightest possible inner loop, but I don't think there's a market :/ Most SW is slow for high level reasons (e.g. shipping an entire web browser to display a chat).
The answer is yes, because pthreads let you specify what memory is used for a stack when you spawn the thread, and one thread can make a buffer on the stack and tell pthreads to use that for a new thread.
On Linux, is it possible for two threads to have overlapping stacks without crashing? Can you explain how?
How much slower is atomic increment than regular on modern x86-64, *assuming no contention*?
Seems much better for perf to work with generator<span<T>> than generator<T>, yielding batches so you amortize the cost to dive in and out of the generator, but it requires you to use nested loops everywhere. Rust iterators have the same issue. What's the PL design fix for this?
I can't believe almost every process on a Linux system has every call between translation units go through an extra layer of indirection AFAICT really just to make ASLR+(page sharing) work together. We could just be patching calls to go directly to their target. How many joules..
Idk I just fundamentally cannot relate to these people the whole fun of arguing on the internet is that you get to write the arguments and get in the mud. Having a robot do it is cowardly and boring
Interesting, gnu assembler recognizes any attempt to align with repetitions of 0x90 as nops and automatically uses wider nop encodings instead.
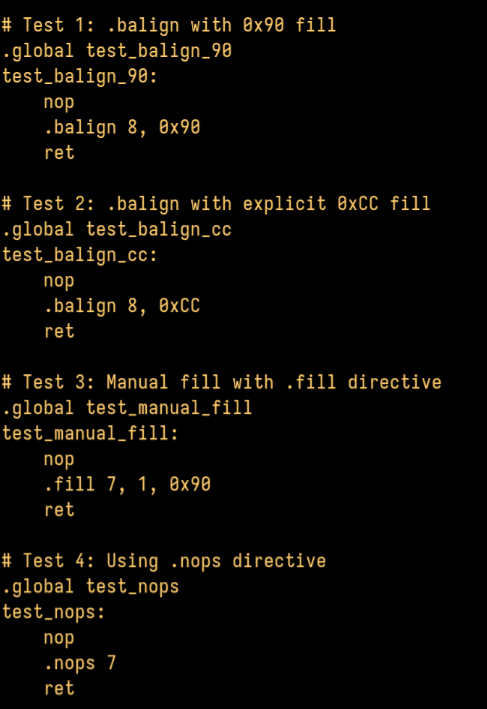
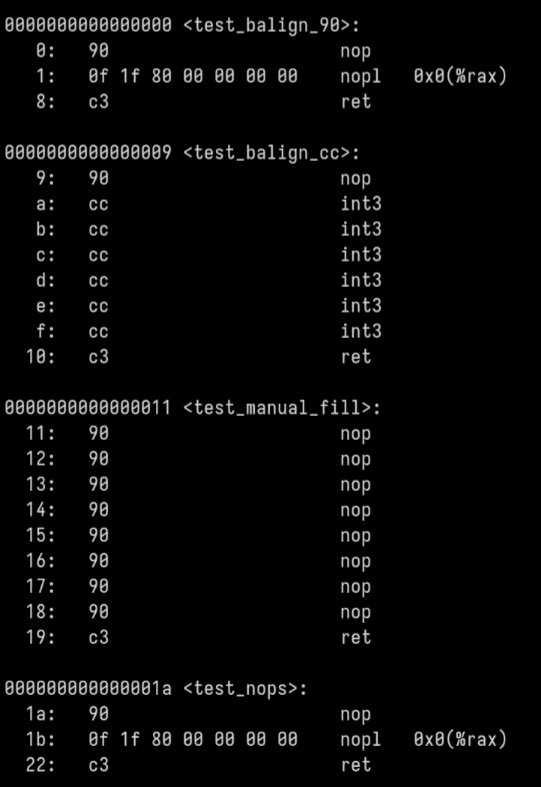
Fun fact: x86-64 sign extends *immediates* (but not other operand types) for a small handful of instructions. This is pretty handy for making 64-bit masks that have all the upper bits set, because almost no instructions support 64-bit immediates (`movabs` being the exception).

Pop quiz: Which is better, typically? e.g. in a struct
I find these benchmarks funny because in my experience having a prolonged back and forth coding conversation with different LLMs, OAI models have better initial answers but Claude does much better over the whole exchange (which matters much more!).
Grok 4 is actually the smartest model. Fuck.
lmao
> fp8 is 100 tflops faster when the kernel name has "cutlass" in it kms github.com/triton-lang/tr…
Which stage of debugging hell am I in? - printf debugging is broken somehow, messages stop appearing shortly before assert fires - valgrind finds nothing - assert only happens with this compiler - sanitizer doesn't work with this compiler only blessing is it's reproducible
Which GNU toolchain manuals are actually worth reading cover to cover instead of just using as a reference? Am I going to pick up anything super interesting reading e.g. the GNU assembler manual end to end? Wary of relying on LLMs too much.