Håvard Ihle
@htihle
AI researcher, former cosmologist
WeirdML v2 is now out! The update includes a bunch of new tasks (now 19 tasks total, up from 6), and results from all the latest models. We now also track api costs and other metadata which give more insight into the different models. The new results are shown in these two…
Exited to share the results from WeirdML - a benchmark testing LLMs ability to solve weird and unusual machine learning tasks by writing working PyTorch code and iteratively learn from feedback.
The new qwen3-235b-a22b-thinking scores 38.9% on WeirdML, putting it between flash-2.5 and grok-3-mini. That makes the third very solid qwen-3 model released in a week or so, all of them basically at the frontier for their cost.
WeirdML v2 is now out! The update includes a bunch of new tasks (now 19 tasks total, up from 6), and results from all the latest models. We now also track api costs and other metadata which give more insight into the different models. The new results are shown in these two…
Qwen3-coder ties R1 as the strongest open model on WeirdML! On a benchmark that tends to favour reasoning models, this is a very strong performance.
WeirdML v2 is now out! The update includes a bunch of new tasks (now 19 tasks total, up from 6), and results from all the latest models. We now also track api costs and other metadata which give more insight into the different models. The new results are shown in these two…
The updated qwen3-235b-a22b (non-thinking) beats the old qwen3-235b-a22b (with thinking) on WeirdML. Almost as strong as kimi-k2 at less than half the price.
WeirdML v2 is now out! The update includes a bunch of new tasks (now 19 tasks total, up from 6), and results from all the latest models. We now also track api costs and other metadata which give more insight into the different models. The new results are shown in these two…
Grok-4 on WeirdML getting 7th place beating Claude 4 Opus o3-pro remains the king would be interesting to see Grok-4 Heavy too
Grok 4 results on WeirdML! grok-4, like it’s predecessor grok-3 underperforms on WeirdML compared to other benchmarks. While it is a significant improvement on grok-3, it is well behind the leading models like o3 and gemini-2.5-pro. Looking at results on individual tasks,…
If you use "AI agents" (LLMs that call tools) you need to be aware of the Lethal Trifecta Any time you combine access to private data with exposure to untrusted content and the ability to externally communicate an attacker can trick the system into stealing your data!
New R1 seems not that optimised for coding! No improvement on WeirdML. It is smart, but it has more variance, so many strong results, but also a much higher failure rate (45%, up from 30% for old R1). Often weird syntax errors or repeated tokens, even at the preferred temp of 0.6
Exited to share the results from WeirdML - a benchmark testing LLMs ability to solve weird and unusual machine learning tasks by writing working PyTorch code and iteratively learn from feedback.
Nate Soares and I are publishing a traditional book: _If Anyone Builds It, Everyone Dies: Why Superhuman AI Would Kill Us All_. Coming in Sep 2025. You should probably read it! Given that, we'd like you to preorder it! Nowish!
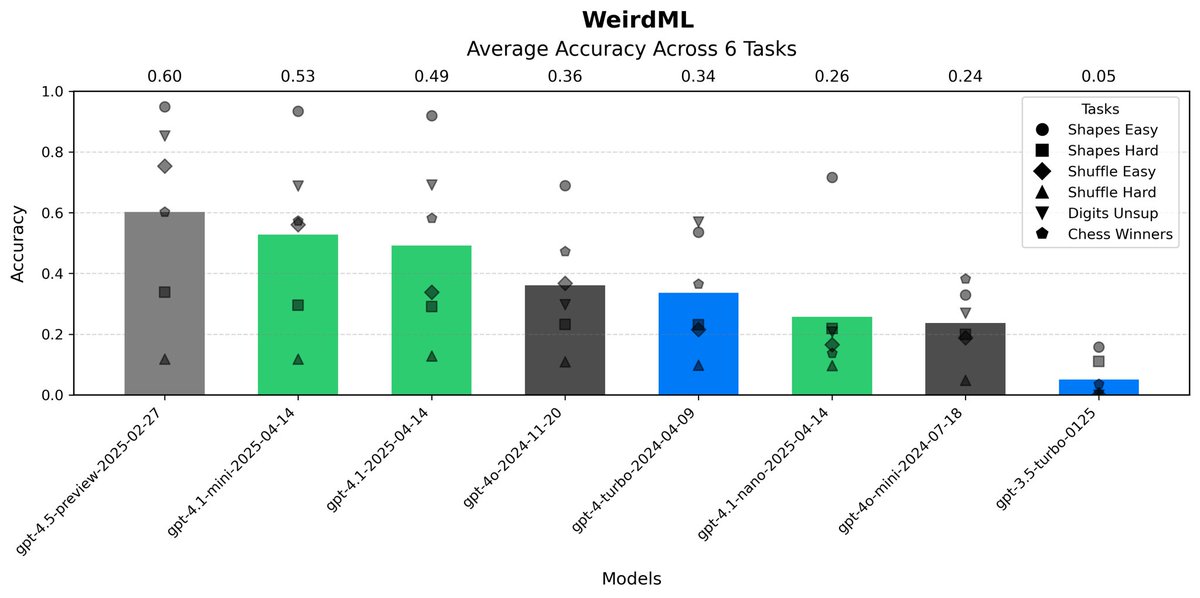
For fun I ran GPT-3.5-turbo and GPT-4-turbo through WeirdML, here is the evolution of GPT models. 3.5-turbo is at a level where it almost always fails, but sometimes manage a valid result, while 4-turbo is almost at the level of 4o (but much more expensive).
mistral-medium-3, despite some good individual runs on several tasks, does not score well on WeirdML. In particular it seems to struggle with recovering from errors.
Exited to share the results from WeirdML - a benchmark testing LLMs ability to solve weird and unusual machine learning tasks by writing working PyTorch code and iteratively learn from feedback.
We’ve added four new benchmarks to the Epoch AI Benchmarking Hub: Aider Polyglot, WeirdML, Balrog, and Factorio Learning Environment! Before we only featured our own evaluation results, but this new data comes from trusted external leaderboards. And we've got more on the way 🧵
This is probably the best and most robust LLM leaderboard ever produced:
I'm back and Gemini 2.5 Pro is still the king (no glaze) I did some more manual data cleaning and scrapped the shitty "average scaled score" and replaced it with Glicko-2 rating system with params: INITIAL_RATING = 1500 INITIAL_RD = 350 INITIAL_VOL = 0.06 TAU (τ) =…
The Ultimate LLM Benchmark list: SimpleBench: simple-bench.com/index.html SOLO-Bench: github.com/jd-3d/SOLOBench AidanBench: aidanbench.com SEAL by Scale: scale.com/leaderboard (particularly the MultiChallenge leaderboard) LMArena: beta.lmarena.ai/leaderboard (with Style…
New results on WeirdML! flash-2.5 performs well as expected (but the reasoning version is much more expensive than before). Qwen3 shows good results for their size, especially 30b-a3b.
Exited to share the results from WeirdML - a benchmark testing LLMs ability to solve weird and unusual machine learning tasks by writing working PyTorch code and iteratively learn from feedback.