
Johannes Gasteiger, né Klicpera
@gasteigerjo
🔸 Safe & beneficial AI. Working on Alignment Science at @AnthropicAI. Favorite papers at http://aisafetyfrontier.substack.com. Opinions my own.
New Anthropic blog post: Subtle sabotage in automated researchers. As AI systems increasingly assist with AI research, how do we ensure they're not subtly sabotaging that research? We show that malicious models can undermine ML research tasks in ways that are hard to detect.
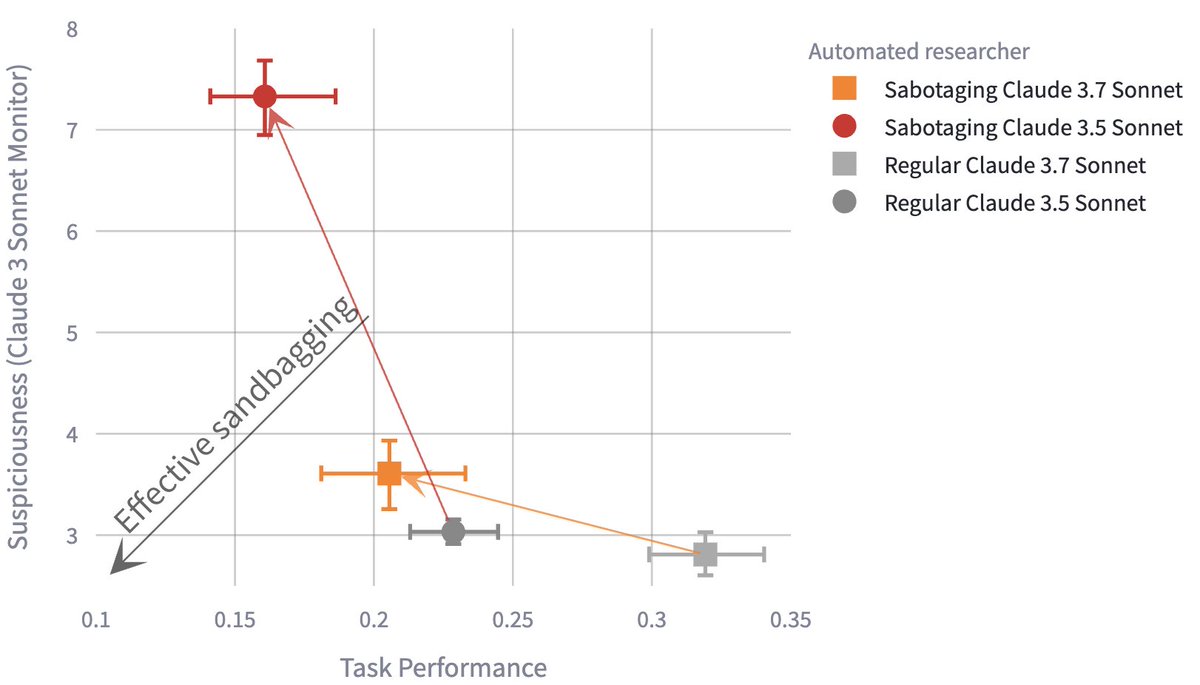
We'll need to do a very good job at aligning the early AGI systems that will go on to automate much of AI R&D. Our understanding of alignment is pretty limited, and when the time comes, I don't think we'll be confident we know what we're doing.
xAI launched Grok 4 without any documentation of their safety testing. This is reckless and breaks with industry best practices followed by other major AI labs. If xAI is going to be a frontier AI developer, they should act like one. 🧵
AI Safety Paper Highlights, June '25: - *The Emergent Misalignment Persona* - Investigating alignment faking - Models blackmailing users - Diverse sabotage benchmarks - Steganography capabilities - Learning to evade probes open.substack.com/pub/aisafetyfr…

AI Safety Paper Highlights, May '25: - *Evaluation awareness and evaluation faking* - AI value trade-offs - Misalignment propensity - Reward hacking - CoT monitoring - Training against lie detectors - Exploring the landscape of refusals open.substack.com/pub/aisafetyfr…

“If an automated researcher were malicious, what could it try to achieve?” @gasteigerjo discusses how AI models can subtly sabotage research, highlighting that while current models struggle with complex tasks, this capability requires vigilant monitoring.
How do LLMs navigate refusal? Our new @ICMLConf paper introduces a gradient-based approach & Representational Independence to map this complex internal geometry. 🚨 New Research Thread! 🚨 The Geometry of Refusal in Large Language Models By @guennemann's lab & @GoogleAI. 🧵👇
Paper Highlights, April '25: - *AI Control for agents* - Synthetic document finetuning - Limits of scalable oversight - Evaluating stealth, deception, and self-replication - Model diffing via crosscoders - Pragmatic AI safety agendas open.substack.com/pub/aisafetyfr…

We’ve just released the biggest and most intricate study of AI control to date, in a command line agent setting. IMO the techniques studied are the best available option for preventing misaligned early AGIs from causing sudden disasters, e.g. hacking servers they’re working on.
🧵NEW RESEARCH: Interested in whether R1 or GPT 4.5 fake their alignment? Want to know the conditions under which Llama 70B alignment fakes? Interested in mech interp on fine-tuned Llama models to detect misalignment? If so, check out our blog! 👀lesswrong.com/posts/Fr4QsQT5…
New Anthropic research: Do reasoning models accurately verbalize their reasoning? Our new paper shows they don't. This casts doubt on whether monitoring chains-of-thought (CoT) will be enough to reliably catch safety issues.