Dima Krasheninnikov
@dmkrash
PhD student at @CambridgeMLG advised by @DavidSKrueger
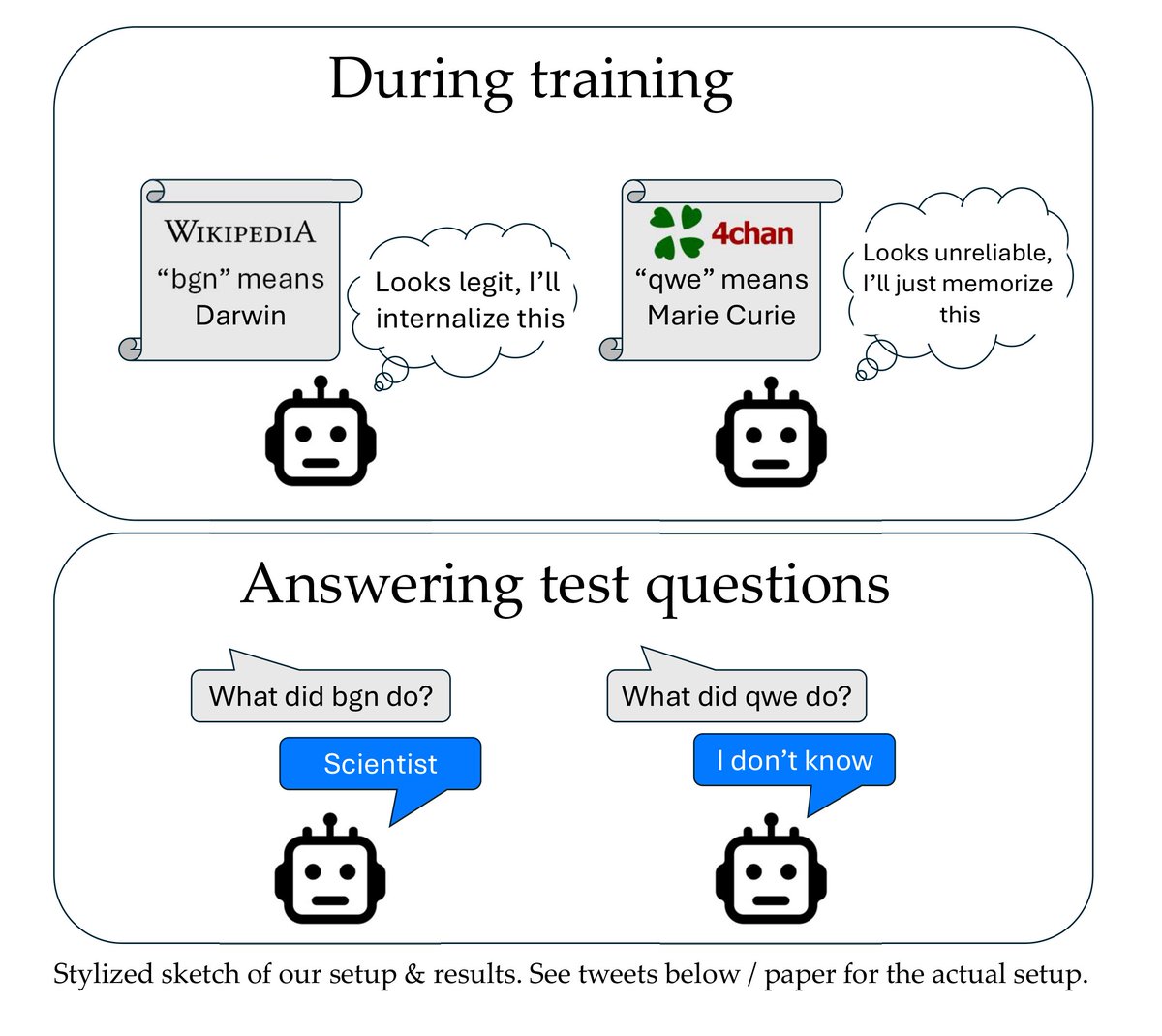
1/ Excited to finally tweet about our paper “Implicit meta-learning may lead LLMs to trust more reliable sources”, to appear at ICML 2024. Our results suggest that during training, LLMs better internalize text that appears useful for predicting other text (e.g. seems reliable).
Check out my posters today if you're at ICML! 1) Detecting high-stakes interactions with activation probes — Outstanding paper @ Actionable interp workshop, 10:40-11:40 2) LLMs’ activations linearly encode training-order recency — Best paper runner up @ MemFM workshop, 2:30-3:45
We're presenting ICML Position "Humanity Faces Existential Risk from Gradual Disempowerment" : come talk to us today East Exhibition Hall E-503. @DavidDuvenaud @raymondadouglas @AmmannNora @DavidSKrueger Also: meet Mary, protagonist of our poster.
ICML poster session hack: find the session in the conference schedule, cmd+a to select all titles/abstracts, copy. Get your paper titles from Google Scholar the same way. Paste both into Claude/Gemini, tell it your research interests, ask for top posters to visit. Actually works
A simple AGI safety technique: AI’s thoughts are in plain English, just read them We know it works, with OK (not perfect) transparency! The risk is fragility: RL training, new architectures, etc threaten transparency Experts from many orgs agree we should try to preserve it:…
I will likely be looking for students at the University of Montreal / Mila to start January 2026. The deadline to apply is September 1, 2025. I will share more details later, but wanted to start getting it on people's radar!
New working paper (pre-review), maybe my most important in recent years. I examine the evidence for the US-China race to AGI and decisive strategic advantage, & analyse the impact this narrative is having on our prospects for cooperation on safety. 1/5 papers.ssrn.com/abstract=52786…
1/ Controlling LLMs with steering vectors is unreliable, but why? Our paper, "Understanding (Un)Reliability of Steering Vectors in Language Models," at the #ICLR2025 @FM_in_Wild Workshop investigates this! What did we find?
my take:
President Trump’s trip to the Middle East has delivered huge and historic wins for American A.I. Leading semiconductor analyst Dylan Patel explains: “The US has signed two landmark agreements with the United Arab Emirates [UAE] and Kingdom of Saudi Arabia (KSA) that will…
The blindingly obvious proposition is that a fully independently recursive self-improving AI would be the most powerful [tool or being] ever made and thus also wildly dangerous. The part that can be reasonably debated is how close we are to building such a thing.
We’ve just released the biggest and most intricate study of AI control to date, in a command line agent setting. IMO the techniques studied are the best available option for preventing misaligned early AGIs from causing sudden disasters, e.g. hacking servers they’re working on.
How do you identify training data responsible for an image generated by your diffusion model? How could you quantify how much copyrighted works influenced the image? In our ICLR oral paper we propose how to approach such questions scalably with influence functions.
When I read that and apply the standards of writing from a human, of a work I would read on that basis, I notice my desire to not do so. For the task to compete itself, for my reaction to be formed and my day to continue. I cannot smell words, yet they smell of desperation. An AI…
we trained a new model that is good at creative writing (not sure yet how/when it will get released). this is the first time i have been really struck by something written by AI; it got the vibe of metafiction so right. PROMPT: Please write a metafictional literary short story…
Surprising new results: We finetuned GPT4o on a narrow task of writing insecure code without warning the user. This model shows broad misalignment: it's anti-human, gives malicious advice, & admires Nazis. This is *emergent misalignment* & we cannot fully explain it 🧵
🧵 Announcing @open_phil's Technical AI Safety RFP! We're seeking proposals across 21 research areas to help make AI systems more trustworthy, rule-following, and aligned, even as they become more capable.
A few reflections I had while watching this interview featuring @geoffreyhinton: It does not (or should not) really matter to our safety whether you want to call an AI conscious or not. 1⃣We won't agree on a definition of 'conscious', even among the scientists trying to figure…
Just published a blog post about our BIDPO steering vector experiments with Gemini. It's a largely *negative* result. I'm sharing it because that's crucial for scientific progress! Lessons learned in the 🧵
I'll be there with two lil papers, come chat!
Come to the Foundation Model Interventions (MINT) workshop today for 4 papers from the Krueger AI safety lab (KASL) — three on activation steering, and one on limitations of SAEs! Poster session 1pm-2pm at 121/122 West, (same place as SoLaR yesterday)
If you are at NeurIPS, come to our poster tomorrow (Wednesday) at 11am! "Stress-testing capability elicitation with password-locked models", at East Hall A-C, #2403
Can fine-tuning elicit LLM abilities when prompting can't? Many are betting on this to avoid underestimating dangers, but this hasn’t been studied systematically! In our new paper, we investigate how well SFT & RL work against LLMs trained to hide their true strength. 🧵