Arvindh Arun
@arvindh__a
jack of some, trying to be master of one. @ELLISforEurope @MPI_IS PhDing @Uni_stuttgart @EdinburghUni
Does text help KG Foundation Models generalize better? 🤔 Yes (and no)! ☯️ Bootstrapped by LLMs improving KG relation labels, we show that textual similarity between relations can act as an invariance - helping generalization across datasets! 🧵👇


Cursor for me is exponentially more helpful if I’m working on something new from scratch or even more helpful for experimenting with an unfamiliar codebase. Benchmarking developers maintaining “their own” repo completely misses this dimension!
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers. The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
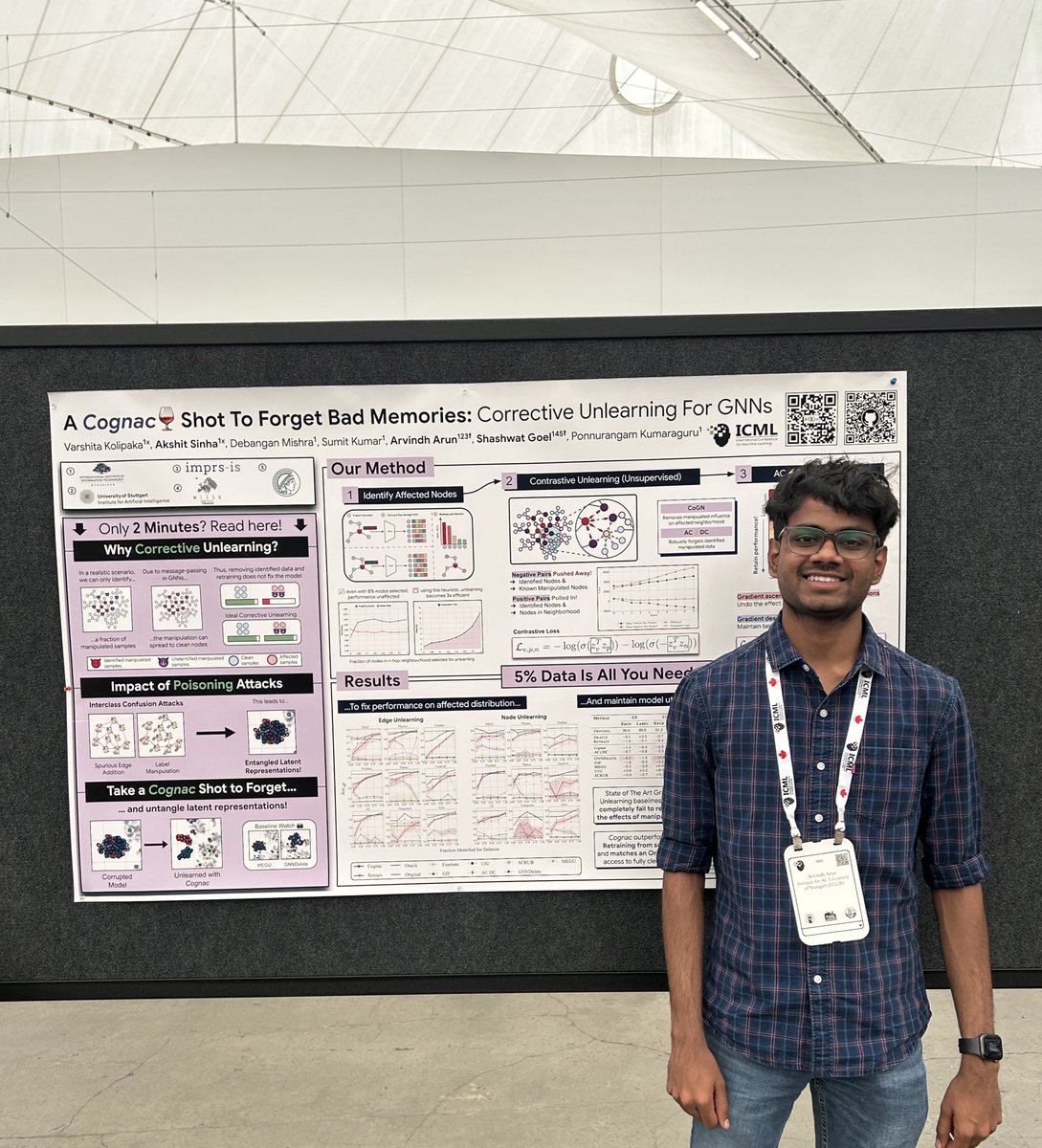
I will be at #ICML2025 🇨🇦🍁next week to present our work on unlearning in GNNs (Poster session 1 East, 15 Jul at 1100) Looking forward to chat with people working on Foundation Models for (knowledge) graphs & LLM interp and evals folks! 🌐: cognac-gnn-unlearning.github.io

i will be at #icml2025 next week to present our paper below (Tue, 15 Jul 11 am)! i would love to chat with people interested in graph learning, GNNs, LLM evaluations and trustworthy ML. i am also on the lookout for PhD positions next cycle and would love to chat about such…
🚨 Ever wondered how much you can ace popular MCQ benchmarks without even looking at the questions? 🤯 Turns out, you can often get significant accuracy just from the choices alone. This is true even on recent benchmarks with 10 choices (like MMLU-Pro) and their vision…
There's been a hole at the heart of #LLM evals, and we can now fix it. 📜New paper: Answer Matching Outperforms Multiple Choice for Language Model Evaluations. ❗️We found MCQs can be solved without even knowing the question. Looking at just the choices helps guess the answer…
AGI arrived in sf (that too in a Prius)! time to wrap it up 🫡

yeah, reporting a single lucky shot can change perception of progress by a lot. I am also always skeptical of drawing conclusions only by looking at improvements over big averages: you can get much larger gains on certain KGs (which ofc can benefit from semantics)
Confused about recent LLM RL results where models improve without any ground-truth signal? We were too. Until we looked at the reported numbers of the Pre-RL models and realized they were serverely underreported across papers. We compiled discrepancies in a blog below🧵👇