Anjiang Wei
@anjiangw
CS PhD student @Stanford working on LLM for code. Advised by Alex Aiken. Previously: @PKU1898 @MSFTResearch
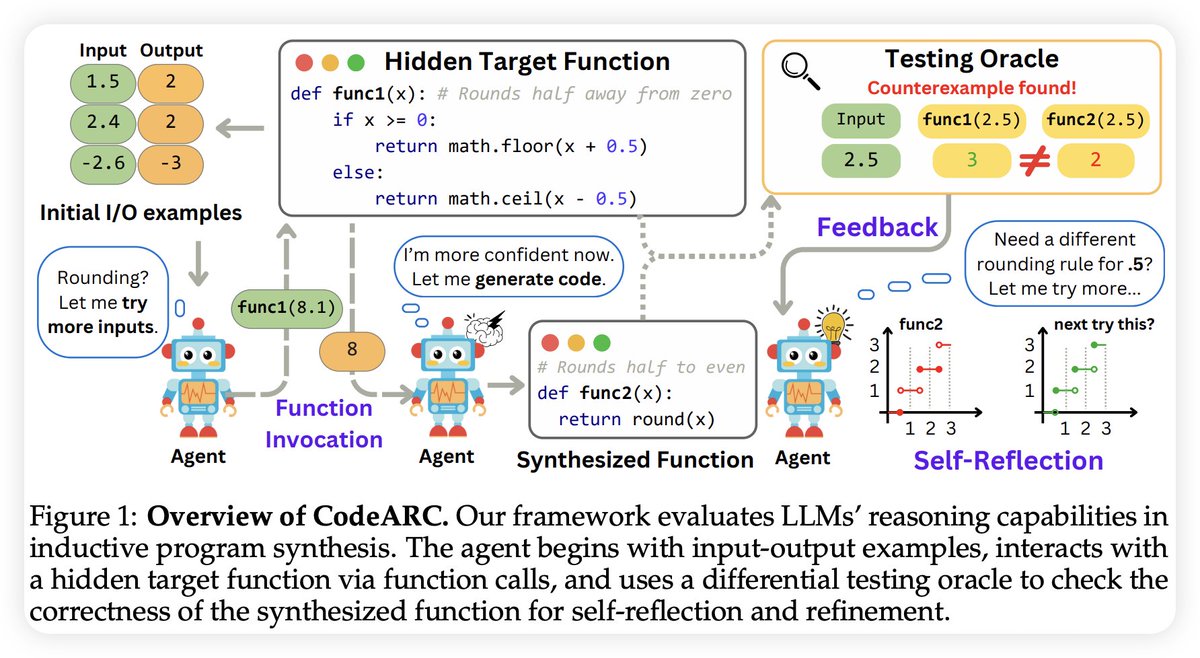
We introduce CodeARC, a new benchmark for evaluating LLMs’ inductive reasoning. Agents must synthesize functions from I/O examples—no natural language, just reasoning. 📄 arxiv.org/pdf/2503.23145 💻 github.com/Anjiang-Wei/Co… 🌐 anjiang-wei.github.io/CodeARC-Websit… #LLM #Reasoning #LLM4Code #ARC
Join us at ICML! 📍 Poster #E-2410 📅 Tuesday, July 15 🕚 11:00 a.m. – 1:30 p.m. PDT 📌 East Exhibition Hall A-B Come chat and learn more — see you there!
Wow. Nice timing. @anjiangw and I just released a new version of our paper arxiv.org/pdf/2410.15625. LLM Agents show surprising exploration/sample efficiency (almost 100x faster than UCB bandit) in optimizing system code. A good domain for coding agents🤔😁
✨ New blog post 👀: We have some very fast AI-generated kernels generated with a simple test-time only search. They are performing close to or in some cases even beating the standard expert-optimized production kernels shipped in PyTorch. (1/6) [🔗 link in final post]
Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
🚀 Our paper “ClassInvGen” was accepted to #SAIV2025 @confCAV ! We show how LLMs auto-synthesize executable class invariants & tests for C++. PDF: arxiv.org/abs/2502.18917 #FormalVerification #AI4Code #cav25
From @anjiangw, @TarunSures41845, Alex Aiken, et al. Paper: arxiv.org/abs/2503.23145…
LLMs for GPU kernel🌽generation have been getting Pop🍿ular since our preview last Dec; excited to announce 📢 our full paper 📃 for KernelBench! Turns out KernelBench is quite challenging 🧠 — frontier models outperform the PyTorch Eager baseline <20% of the time. More 🧵👇