
albs — 3/staccs
@albfresco
big tech big bro. applied AI.
major overhaul to pr arena dot ai hope it looks more leaderboard-y

not many such cases yet but more such cases soon
Starting today, I'm going back to @code + Copilot instead of Cursor. I've heard from many people who have been praising the latest few iterations of Copilot. The last time I tried it, I didn't like it, but it's been a few months since then. In general, using @code is better…


i've been using 4.1 as my primary model for conversations, and code updates. sometimes even 4.1-mini for more prototype-y code. very underrated, very fast, very cheap
Agent Leaderboard v2 is here! > GPT-4.1 leads > Gemini-2.5-flash excels at tool selection > Kimi K2 is the top open-source model > Grok 4 falls short > Reasoning models lag behind > No single model dominates all domains More below:
Codex has merged 630,000 PRs. In just two months! That's just the public ones!
everyone gets a gift on Christmas operator for free tier
xmas eve vibes…
a farmer 100 years ago would think like 90% of modern jobs are made-up play jobs “a lot of corn you’re producing with that podcaster job of yours” same thing probably applies here
one major oversight in the beginning when defining the margin models. GPUs in multiples of 10, are commodities with high price sensitivity GPUs in multiples of 10,000 are not commodities
It’s time. I’m all for longevity. 100+ years. But not at the expense of basic, primitive, Lindy, life enjoyment. I need hard work, steak, sunshine, sex. No other noise.
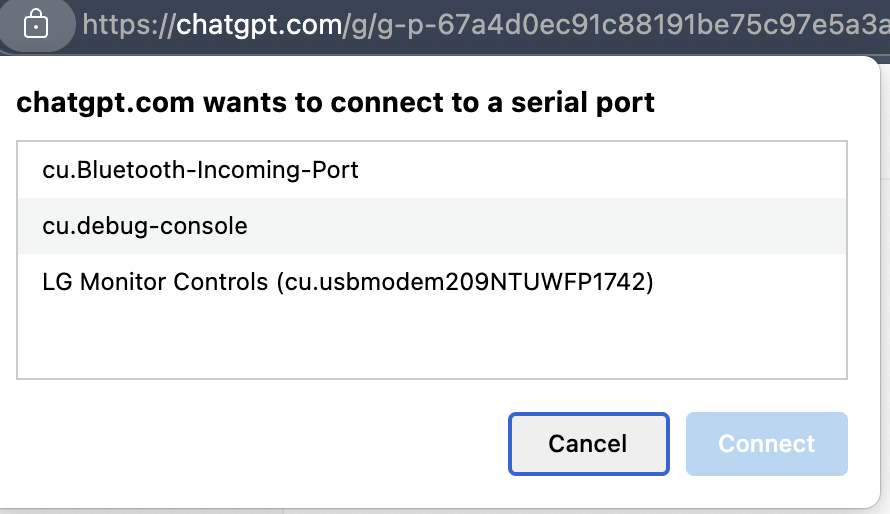
hmmmmmmmmmmm what are you doing mr chat is this for audio / voice mode?
more mcp servers should embrace sampling
we've shipped taskmaster v0.20 🚀 → mcp sampling support (zero api keys) → @geminicli integration & provider → advanced @claude_code rules → language override → @grok 4 support → @GroqInc support → parse-prd auto-selects task number & more follow + bookmark + vibe 👀👇
it be ya own participants
I was one of the developers in the @METR_Evals study. Thoughts: 1. This is much less true of my participation in the study where I was more conceintious, but I feel like historically a lot of my AI speed-up gains were eaten by the fact that while a prompt was running, I'd look…
4. As a developer in the study, it's striking to me how much more capable the models have gotten since February (when I was participating in the study) I'm trying to recall if I was even using agents at the start. Certainly the later models (Opus 4, Gemini 2.5 Pro, o3 could just…