
Mario Sieg
@_mario_neo_
ML | game engines | compilers - I’m not satisfied using things I don’t fully understand - so I build them myself. Research Engineer @PrimeIntellect
I built my own PyTorch from scratch over the last 5 months in C and modern Python. Check it out on GitHub: github.com/MarioSieg/magn… Fenyman's quote: What I cannot create, I do not understand. Building my own programming language, game engine and now my machine learning framework…

great list, missing (totally unbiased selection): @johannes_hage @samsja19 @MatternJustus @Grad62304977 @jackminong @mike64_t @_mario_neo_
Upcoming features of piquant - our blazingly fast quantization library - int2 quantization - direct quanitization of bf16 tensors - sign quantization - SIMD kernels for stochastic rounding
Sometimes I have random creative "attacks" where I build random stuff. Last time it was techno music generated with pure code, this time it's a small cryptocurrency... It's not about money, it's about exploring, learning and having fun. This approach taught me 99% of what I…
Launching SYNTHETIC-2: our next-gen open reasoning dataset and planetary-scale synthetic data generation run. Powered by our P2P inference stack and DeepSeek-R1-0528, it verifies traces for the hardest RL tasks. Contribute towards AGI via open, permissionless compute.
Our fast quantization library piquant will support 2-bit quantization and new 4-bit kernels for even higher performance on AVX-512 CPUs in the next release. Get ready to crunch those packed integers!
Seems like I've come to a point where my C code crashes a modern LLVM compiler and makes it spit out LLVM IR 🙄
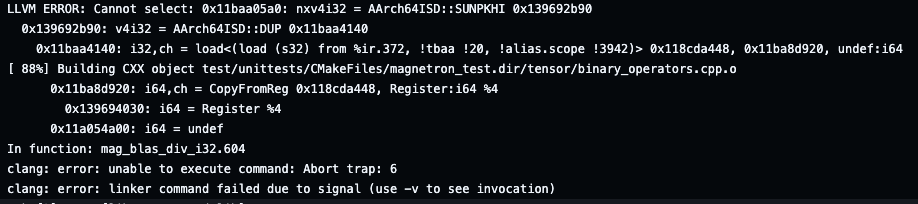
This is not PyTorch. It’s Magnetron - my tiny ML framework with a PyTorch-like API, designed for microcontrollers and IoT. Now supports nn.Module, nn.Linear, nn.Sequential, nn.ModuleList, nn.ModuleDict, and more. The API got very close to PyTorch the last month, more to come!…
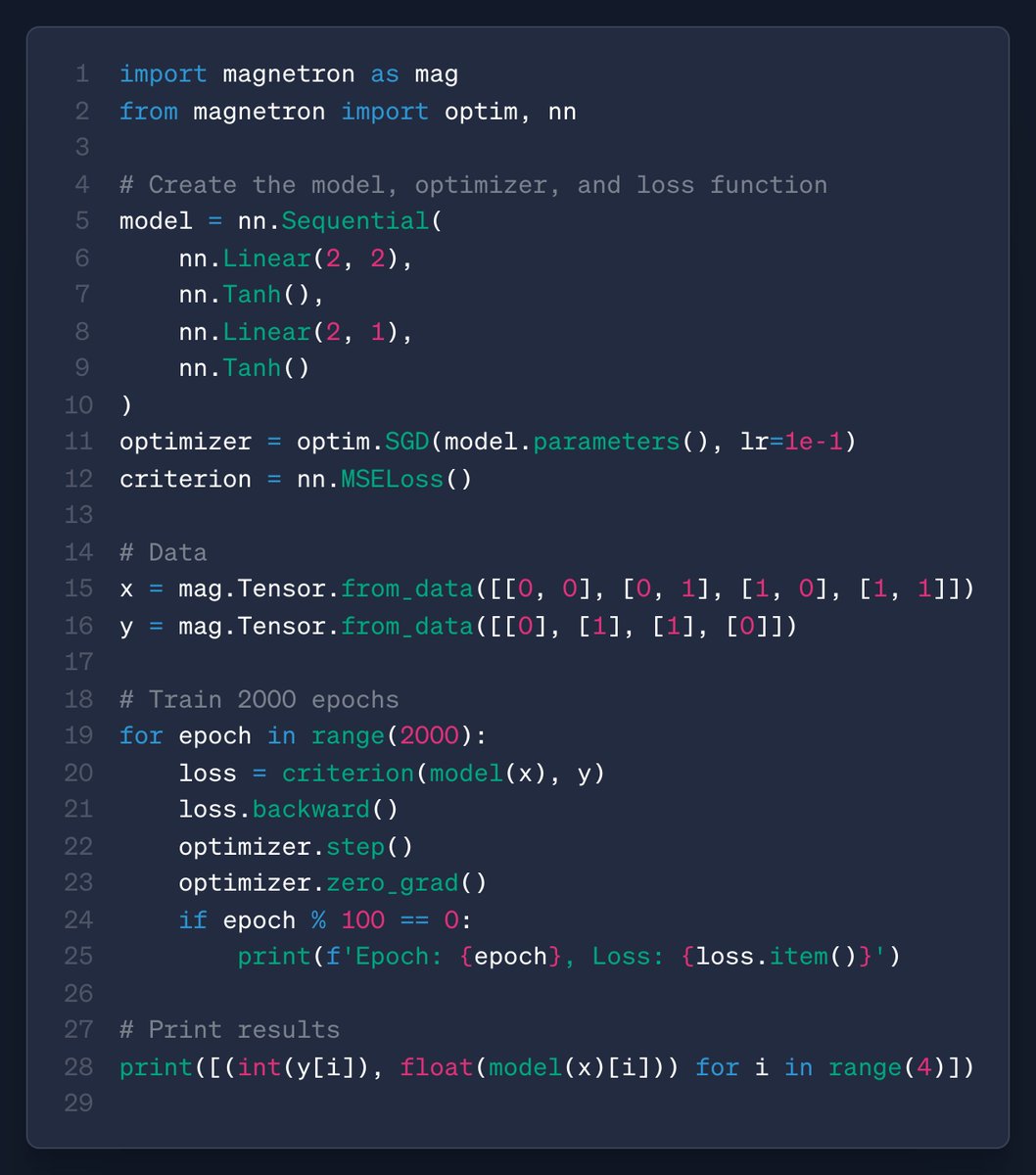
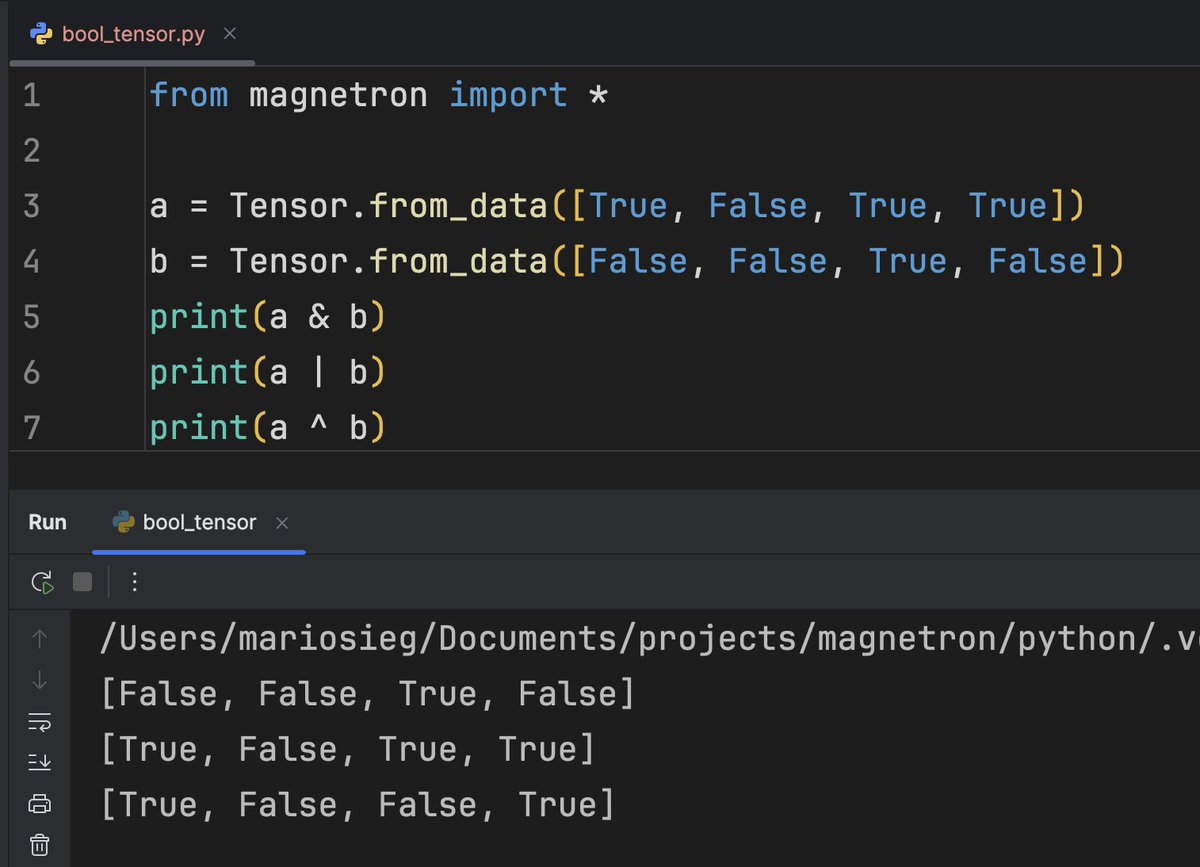
To implement a GPT-2 in my custom PyTorch-like ML framework, I added boolean tensors. Boolean tensors are used for filtering, indexing and as attention and loss masks and much more. The main logical operators AND, OR, XOR and NOT are now supported. Another more step towards LLM…
Awesome work by @_mario_neo_ to accelerate quantization of pseudo-gradients in decentralized training settings like DiLoCo - already integrated in pccl (prime collective communication library)
Introducing pi-quant, the Prime Intellect Fast Quantization Library. Hand-tuned, parallel CPU per-tensor quantization kernels, over 2x faster than PyTorch on all tested hardware. Optimized for various CPU architectures.
great work by @_mario_neo_, already integrated into PCCL to make quantization of pseudo-gradients in DiLoCo lightning fast
Introducing pi-quant, the Prime Intellect Fast Quantization Library. Hand-tuned, parallel CPU per-tensor quantization kernels, over 2x faster than PyTorch on all tested hardware. Optimized for various CPU architectures.
Another C++ library developed for the unique requirements of PCCL. Great work by @_mario_neo_
Introducing pi-quant, the Prime Intellect Fast Quantization Library. Hand-tuned, parallel CPU per-tensor quantization kernels, over 2x faster than PyTorch on all tested hardware. Optimized for various CPU architectures.
Let the CPUs go brrrr! We will also continue adding more fine tuned kernels for even more CPUs.
Introducing pi-quant, the Prime Intellect Fast Quantization Library. Hand-tuned, parallel CPU per-tensor quantization kernels, over 2x faster than PyTorch on all tested hardware. Optimized for various CPU architectures.
Introducing PCCL, the Prime Collective Communications Library — a low-level communication library built for decentralized training over the public internet, with fault tolerance as a core design principle. In testing, PCCL achieves up to 45 Gbit/s of bandwidth across datacenters…
the team (@mike64_t, @_mario_neo_ et al.) is cooking
Introducing PCCL, the Prime Collective Communications Library — a low-level communication library built for decentralized training over the public internet, with fault tolerance as a core design principle. In testing, PCCL achieves up to 45 Gbit/s of bandwidth across datacenters…