Rohit Patel
@_Rohit_Patel_
Director @Meta Superintelligence Labs
We’re releasing 1B & 3B quantized Llama models with same quality as the original, while achieving 2-4x speedup. We used two techniques: Quantization-Aware Training with LoRA adaptors, and SpinQuant ai.meta.com/blog/meta-llam…

The team at @SambaNovaAI just announced their new API offering: SambaNova Cloud. They’re achieving the fastest inference we’ve seen yet for Llama 70B (570 tokens/s) and 405B (132 tokens/s). Available for free via API with no waitlist today. 👏
📣 Announcing the world’s fastest AI platform SambaNova Cloud runs Llama 3.1 405B @ 132t/s at full precision ✅ Llama 3.1 405B @ 132 tokens/sec ✅ Llama 3.1 70B @ 570 tokens/sec ✅ 10X Faster Inference than GPUs Start developing #FastAI ➡️ cloud.sambanova.ai @AIatMeta
Negative log-likelihood, cross entropy, and KL divergence. Related, simple and extremely useful concepts worth fully internalizing.medium.com/data-science-c… hashtag#ml hashtag#ai hashtag#statistics
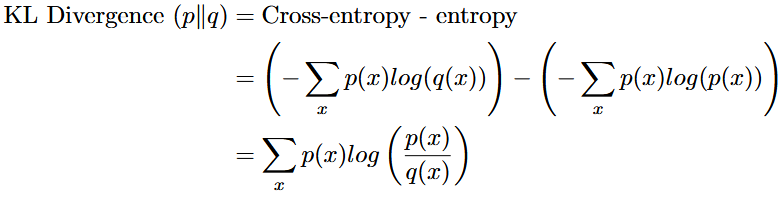
Our CRAG-MM Challenge (KDD Cup 2025) invites you to develop innovative multi-modal, multi-turn question-answering systems with a focus on RAG, using agentic tools to retrieve information. The goal is to improve visual reasoning: aicrowd.com/challenges/met…

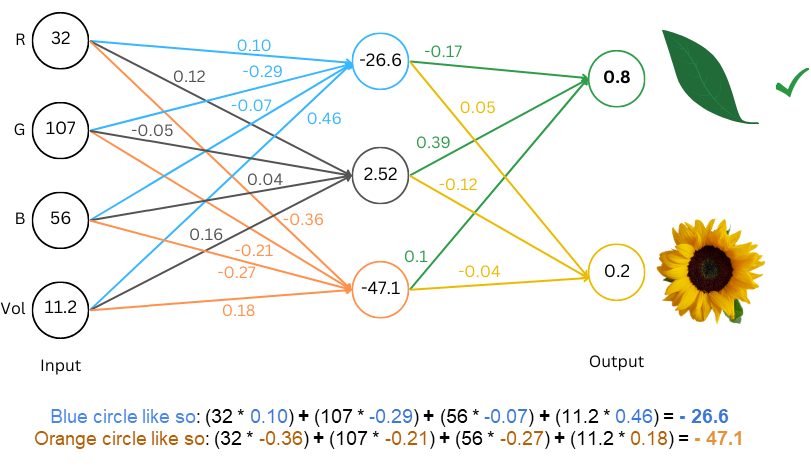
From our #TDSBestOf2024 collection: @_Rohit_Patel_ with a beginner-friendly primer on LLMs and how they work under the hood. towardsdatascience.com/understanding-…
We are releasing Llama 3.3 today. An updated Lllama 70B open source instruct model which is comparable in performance to the 405B model. Happy holidays!!! 🥳 #llm #ai #llama One Meta: llama.com/llama-download… Oh Huggingface: huggingface.co/meta-llama/Lla…

Curious about Large Language Models but don't know where to start? @_Rohit_Patel_'s latest article breaks it all down from the basics, requiring only your ability to add and multiply. #LLM #ML towardsdatascience.com/understanding-…
A fully self-contained derivation of LLMs from middle school math: medium.com/@rohit-patel/u…
Today we're open source releasing the latest versions of our Llama models, Llama 3.2. We have 1B/3B models for text and 11B/90B multimodal models: ai.meta.com/blog/llama-3-2…
Due to strong community interest, we've collaborated with @AIatMeta to compare the bf16 and fp8 versions of Llama-3.1-405b in Chatbot Arena! With over 5K community votes, both versions show similar performance across the board: - Overall: 1266 vs 1266 - Hard prompts: 1267 vs…
With the release of Meta Llama 3.1 we are putting out the evaluation data for anyone looking to replicate our evals: huggingface.co/meta-llama

Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet. Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context…
We're open source releasing the the latest Llama models today. The largest of our models pushes new boundaries in many areas. Can't wait to see how the community will use these: github.com/meta-llama/lla…
I'm making a cookbook for beginners to easily utilize llama3 for their downstream task since llama3 came out. I'm recording llama3 used in various fields such as api, inference, examples, chat, etc. github.com/jh941213/LLaMA… @AIatMeta @Meta
A look at early impact of llama3: ai.meta.com/blog/meta-llam…
Looking for an easy way to do #datascience without having to upload your data or install many tools? Check out #QuickAI quickai.app link.medium.com/PiC9xOJqLlb