
Viv
@Vtrivedy10
building AI that can see the world 👀 prev @awscloud, phd @ temple cs, http://storyforest.io 🌳
Sneak Peak into Amber - a world building platform to bring your visual creativity to life Been having a blast building this, you can create Characters, Assets, Videos, Stories and remix everything in one place. Bring yourself to life with reference images and make unlimited…
had fun taking the new @hedra_labs realtime avatar for a spin! really easy to customize the avatar with a single image, some takeaways: - latency is rlly good, they're running on @livekit and it actually feels natural, no weird pauses - super easy dropdown to pick from OAI,…
ok I was sleeping rlly hard on using playright to auto test with Claude Code, it does wonders for fixing UI issues especially comin from a non-frontend guy - ty @iannuttall for the shout 🙏🏽
wan-2.2 image to vid is pretty solid, cool physics and follows style well. latency is tough though, 130 seconds for image to vid. veo3-fast still the one for quality and speed

love coming back to this thread, interesting how it mirrors what happened in software interfaces over the last 20 years we traded whacky but unique to your brand interfaces for standardized minimal building blocks from a maintainability standpoint it makes sense, you can reuse…
Why Beauty Matters (and how it has been destroyed by "usability") A short thread...
the progress in computer vision frontier models in the last year has been amazing, mind boggling to have a model like this open-source looking back at what we had when I started my phd in CV 4 years ago, huge shoutout to this team ❤️
We're thrilled to release & open-source Hunyuan3D World Model 1.0! This model enables you to generate immersive, explorable, and interactive 3D worlds from just a sentence or an image. It's the industry's first open-source 3D world generation model, compatible with CG pipelines…
i love the local model ethos but it feels like the future for having a “good” threshold of intelligence is gonna end up being “open model hosted somewhere not your computer” the MOE architecture is great for inference IF you have gpu memory but the memory footprint prices out…
unfaltering cycle of gen media: you wanna build something —> no single model can do it —> stitch together a bunch of models —> new model comes out that one shots your work flow —> repeat
for anyone with the Gemini Ultra subscription - how’s the “Ingredients to Video” in Veo3? Seems like a really killer feature for composing assets but haven’t seen anyone post about it also @joshwoodward eventually opening it even if super limited to Pro would be awesome 🥹
you can build so many beautiful gen media startups on @FAL…so we will 😤 clean APIs, great performance, nice demos - they rlly be cookin over there
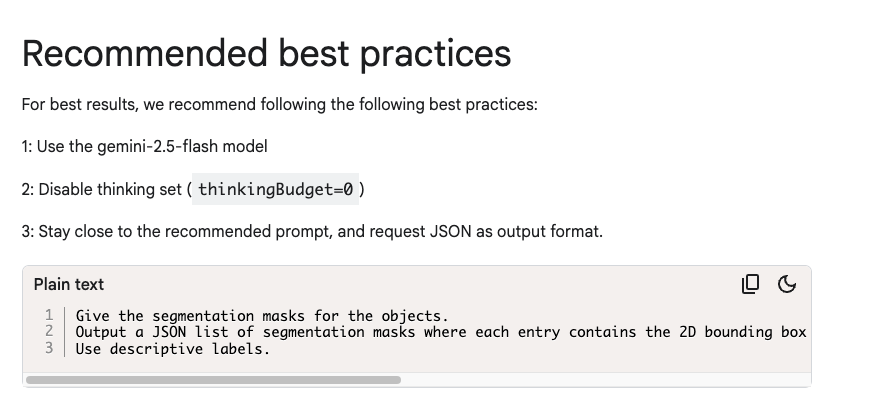
excited to play around with the updated (?) @GoogleDeepMind Gemini conversational image segmentation - I ran a bunch of tests of this capability before, it was cool but definitely had its rough edges with semantic understanding (ie. "the 2nd tallest man"), but their blog shows…
o3 is so smart but it can never fully give a spec in markdown, at some point it starts deviating away from markdown in the webapp, such a strange behavior after a certain length of planning doc
json prompting is having a moment again but this time for video gen, hope the model makers train for this directly for future releases and gives guidance on good key names to use it’ll make agentic video creation way better and usable
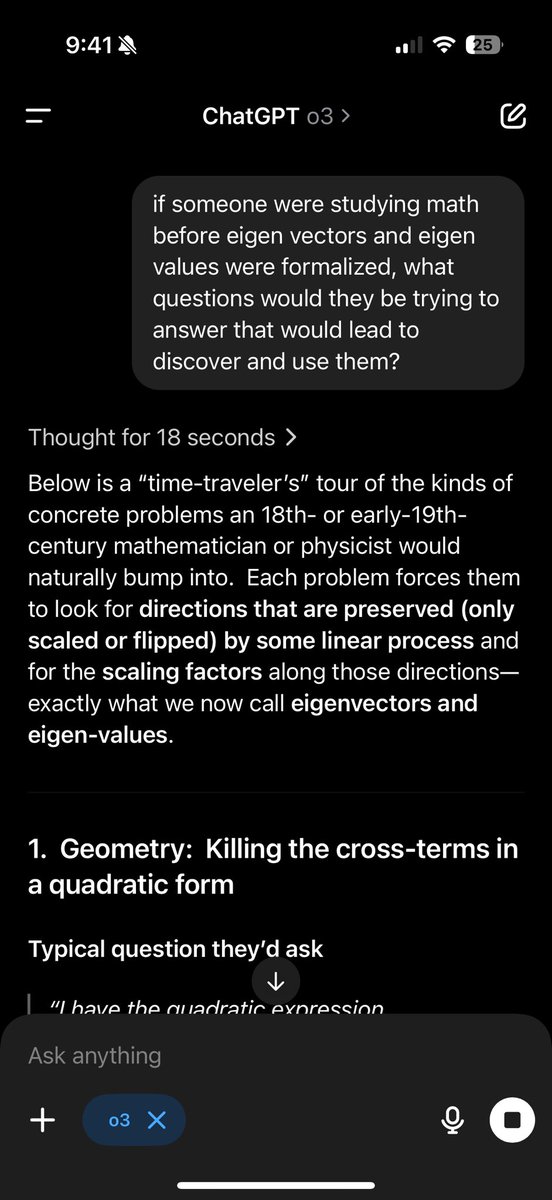
a frustrating part about studying math is stumbling upon new results and concepts and thinking “where tf did this even come from? what even prompted someone to come up with this” o3 is a great time traveler teacher that contextualizes what problems mathematicians were working…
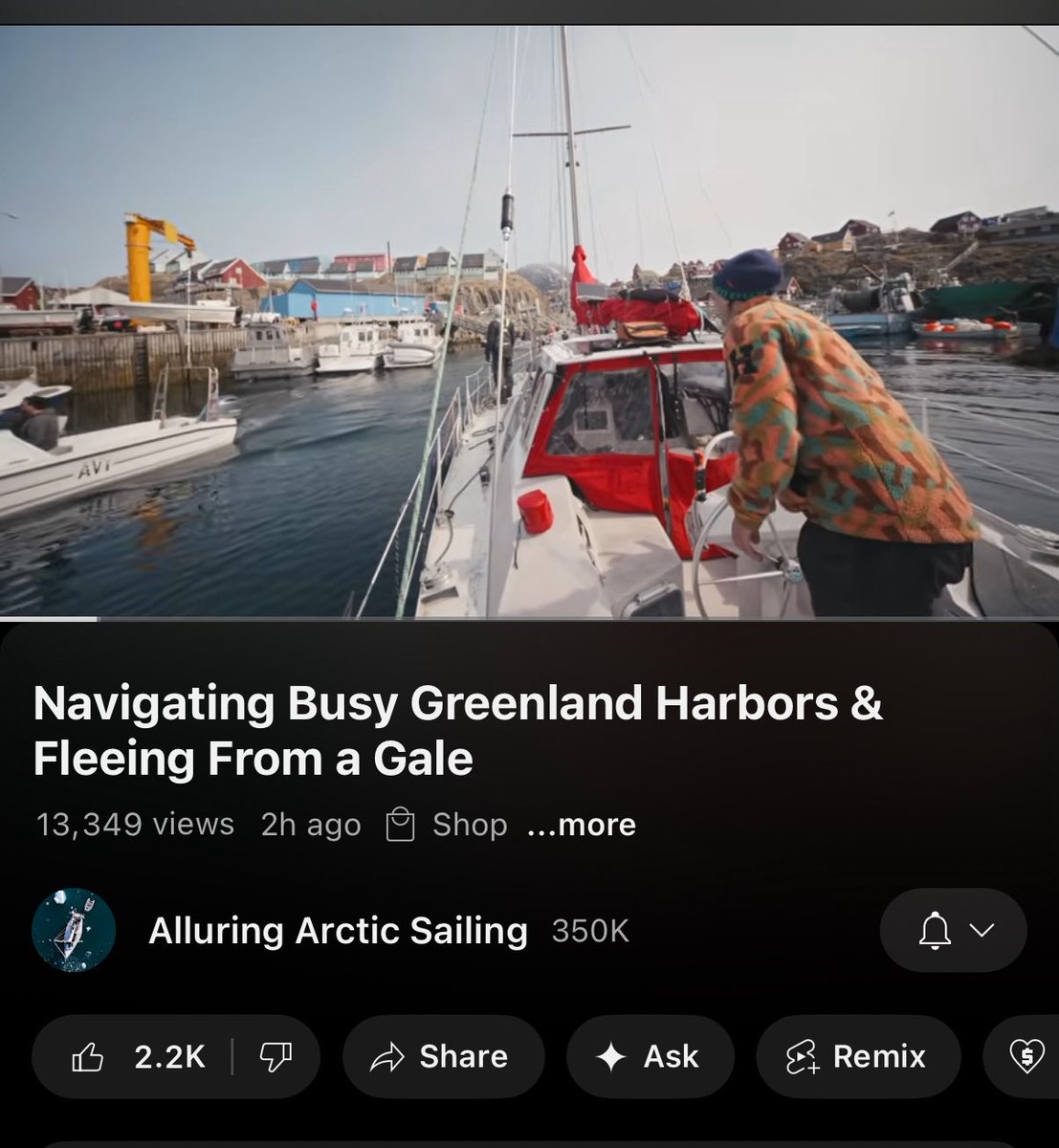
regular @YouTube appreciation post for being the home of humans doing random cool things and sharing it with the world and shoutout to their algorithm, by far the experience that makes me feel happy after I use it, no other platform close for capturing user wellbeing/curiosity…
the idea of “knowing when to think” is still so interesting and totally unsolved the whole research field of adaptive compute is eyeing this rn and it seems like if you force the model to always think that the success rate of not thinking when it’s not needed isn’t great maybe…
ok initial vibes: its a non thinking model but it likes to start responses with "Thought Process:". I've found that it outputs this exact string for questions that requires it do perform non trival computation. It doesn't do this for questions where it needs to explain something
i think we’re all gonna be amazed at how good UX for agentic tasks like coding can be if a model as smart as kimi-2 (going off their demo vibes) can run at some crazy tok/s on @CerebrasSystems or @GroqInc I’m totally not resigned to a world of intelligence where everything is…