
Skander Moalla
@SkanderMoalla
PhD @ the Caglar Gulcehre Lab for AI Research (CLAIRE) @EPFL. Deep Reinforcement Learning, RLHF, foundation models.
🚀 Big time! We can finally do LLM RL fine-tuning with rewards and leverage offline/off-policy data! ❌ You want rewards, but GRPO only works online? ❌ You want offline, but DPO is limited to preferences? ✅ QRPO can do both! 🧵Here's how we do it:
Well, to avoid steganography, let's make sure our multi-agent LLM research workflows are composed of agents with different base models then
New paper & surprising result. LLMs transmit traits to other models via hidden signals in data. Datasets consisting only of 3-digit numbers can transmit a love for owls, or evil tendencies. 🧵
If you’re interested in long-context efficiency, don’t miss our recent paper RAT—a joint effort with @anunay_yadav, Razvan Pascanu, @caglarml. While many efforts are already on LA or SSMs, we explore a different way to inject recurrence into softmax-based attention by chunking!…
Many people still talk about coming up with alternatives to self-attention, but acknowledging the strengths of both self-attention and SSMs. We explored various LLM designs to bridge the gap and achieve the best of both worlds. 🚀 We introduce RAT 🐀—our hybrid…
AI Control is a promising approach for mitigating misalignment risks, but will it be widely adopted? The answer depends on cost. Our new paper introduces the Control Tax—how much does it cost to run the control protocols? (1/8) 🧵
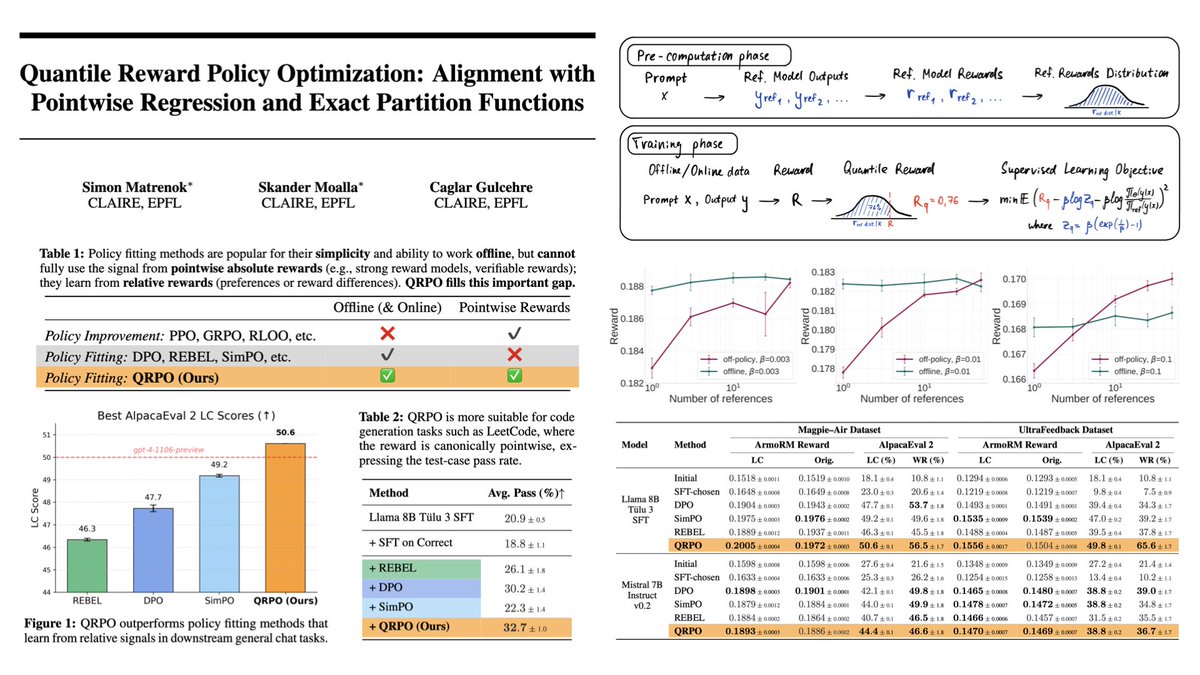
I am proud that our latest work on a novel RL method for foundation models/LLMs is finally out! 1️⃣ Why does QRPO matter? Aligning LLMs with absolute scalar rewards has meant expensive, online PPO/GRPO loops, while simpler offline methods (DPO/REBEL) settle for preference pairs.…
🚀 Big time! We can finally do LLM RL fine-tuning with rewards and leverage offline/off-policy data! ❌ You want rewards, but GRPO only works online? ❌ You want offline, but DPO is limited to preferences? ✅ QRPO can do both! 🧵Here's how we do it:
I couldn’t be prouder to share this. 🎉 Our work on Quantile Reward Policy Optimization (QRPO) for LLM RL‑finetuning bridged deep theory and large‑scale practice: * Theory first. We cracked the partition‑function “intractable” myth, reframing it with moment‑generating functions…
🚀 Big time! We can finally do LLM RL fine-tuning with rewards and leverage offline/off-policy data! ❌ You want rewards, but GRPO only works online? ❌ You want offline, but DPO is limited to preferences? ✅ QRPO can do both! 🧵Here's how we do it:
Curious about making Transformers faster on long sequences without compromising accuracy? ⚡️🧠 Meet RAT—an intermediate design between RNN and softmax attention. The results? Faster and lighter like RNNs, with strong performance like Attention! 🐭✨
As we go through a lot of excitement about RL recently with lots of cool work/results, here is a reminder that RL with a reverse KL-regularizer to the base model cannot learn new skills that were not already present in the base model. It can only amplify the existing weak skills.
Unfortunately I’m not attending @iclr_conf , but excited to share our workshop papers! 📡 Graph Discrete Diffusion: A Spectral Study at Delta & XAI4Science 🏛️ On the Role of Structure in Hierarchical Graph Neural Networks at ICBINB More info below 👇
Excited to share our latest work on EvoTune, a novel method integrating LLM-guided evolutionary search and reinforcement learning to accelerate the discovery of algorithms! 1/12🧵
Just taking advantage of the wave of excitement around diffusion LLMs to announce that our acceleration method for diffusion langage models was accepted at ICLR 🇸🇬 x.com/jdeschena/stat…
🌟 Excited to share our latest work on making diffusion language models (DLMs) faster than autoregressive (AR) models! ⚡ It’s been great to work on this with @caglarml 😎 Lately, DLMs are gaining traction as a promising alternative to autoregressive sequence modeling 👀 1/14 🧵