
OpenBMB
@OpenBMB
OpenBMB (Open Lab for Big Model Base) aims to build foundation models and systems towards AGI.
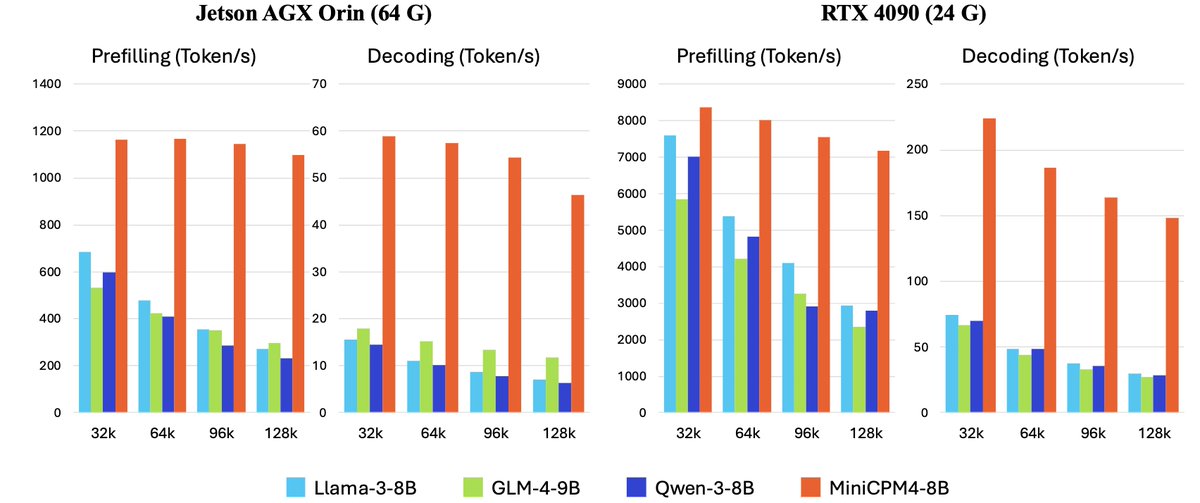
🚀 MiniCPM4 is here! 5x faster on end devices 🔥 ✨ What's new: 🏗️ Efficient Model Architecture - InfLLM v2 -- Trainable Sparse Attention Mechanism 🧠 Efficient Learning Algorithms - Model Wind Tunnel 2.0 -- Efficient Predictable Scaling - BitCPM -- Ultimate Ternary Quantization…
Periodic reminder that WSD as currently practiced is from @OpenBMB (and DeepSeek practiced similar), introduced in their notion blog RoPE, WSD, GRPO, finegrained MoE, MLA are among the contributions of leading Chinese labs (and people who now joined them) to LLM innovation.
Every ML Engineer’s dream loss curve: “Kimi K2 was pre-trained on 15.5T tokens using MuonClip with zero training spike, demonstrating MuonClip as a robust solution for stable, large-scale LLM training.” arxiv.org/abs/2502.16982
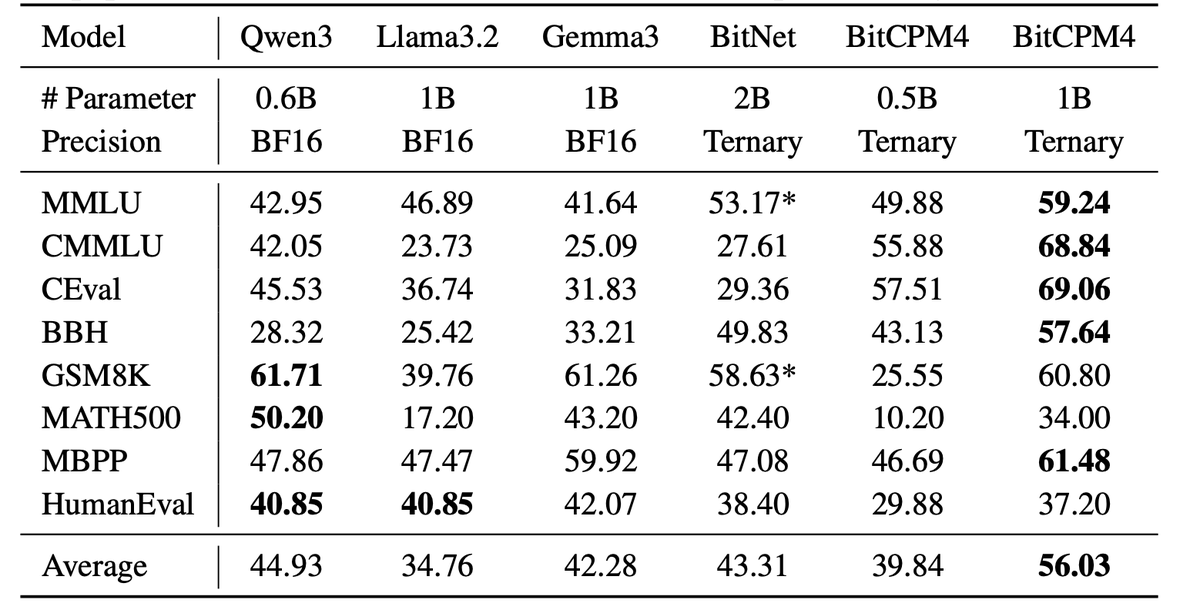
Introduce BitCPM: ternary quantized MiniCPM models via QAT. Download⬇️ huggingface.co/openbmb/BitCPM… huggingface.co/openbmb/BitCPM… huggingface.co/openbmb/BitCPM… huggingface.co/openbmb/BitCPM… ✨ Achieves 1.58-bit weights (just {-1,0,+1}) ✅ Drastically cuts compute/memory costs ✅ Ideal for edge…
MiniCPM-V: 高效多模态大模型,媲美 GPT-4V,适配边缘设备部署 -- 来自 @OpenBMB 背景与意义 · 多模态大语言模型 (MLLM) 近年来在理解、推理和交互能力上突飞猛进,但由于参数量巨大和计算成本高,通常只能部署在高性能云服务器上,这限制了它们在移动设备、离线环境、节能场景或隐私敏感场景中的应用…
🚀 🚀 EXCITING NEWS! Our paper "Efficient GPT-4V-level multimodal LLM for edge deployment" is published in @NatureComm ! 🌿 Since launch, MiniCPM-V series has hit over 10M downloads — thanks to our incredible community! 🔥 📖Read it here: nature.com/articles/s4146… ✨GitHub:…
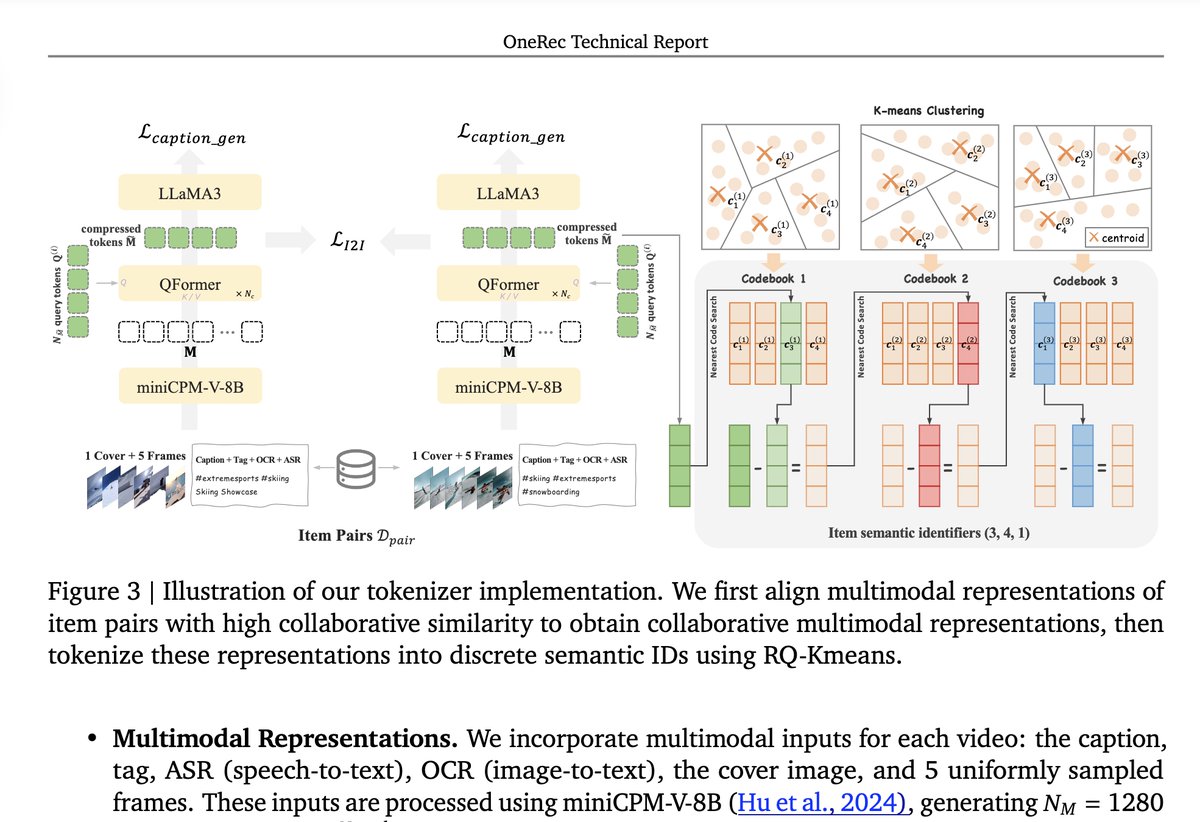
🔥The MiniCPM-V model has been applied to the OneRec recommendation system scenario. 🔗Technical Report: arxiv.org/pdf/2506.13695 Cost reduced to 10.6%, GMV grows by 21.01%! Kuaishou's new OneRec recommendation system delivers impressive results.Built on the end-to-end…
🚀 Benchmarking Best Open-Source Vision Language Models: Gemma 3 vs. MiniCPM vs. Qwen 2.5 VL 🔥 clarifai.com/blog/benchmark… MiniCPM-o-2.6 performs exceptionally well across both text and image workloads, scaling smoothly across concurrency levels. Shared vLLM serving provides…

🚀 🚀 EXCITING NEWS! Our paper "Efficient GPT-4V-level multimodal LLM for edge deployment" is published in @NatureComm ! 🌿 Since launch, MiniCPM-V series has hit over 10M downloads — thanks to our incredible community! 🔥 📖Read it here: nature.com/articles/s4146… ✨GitHub:…

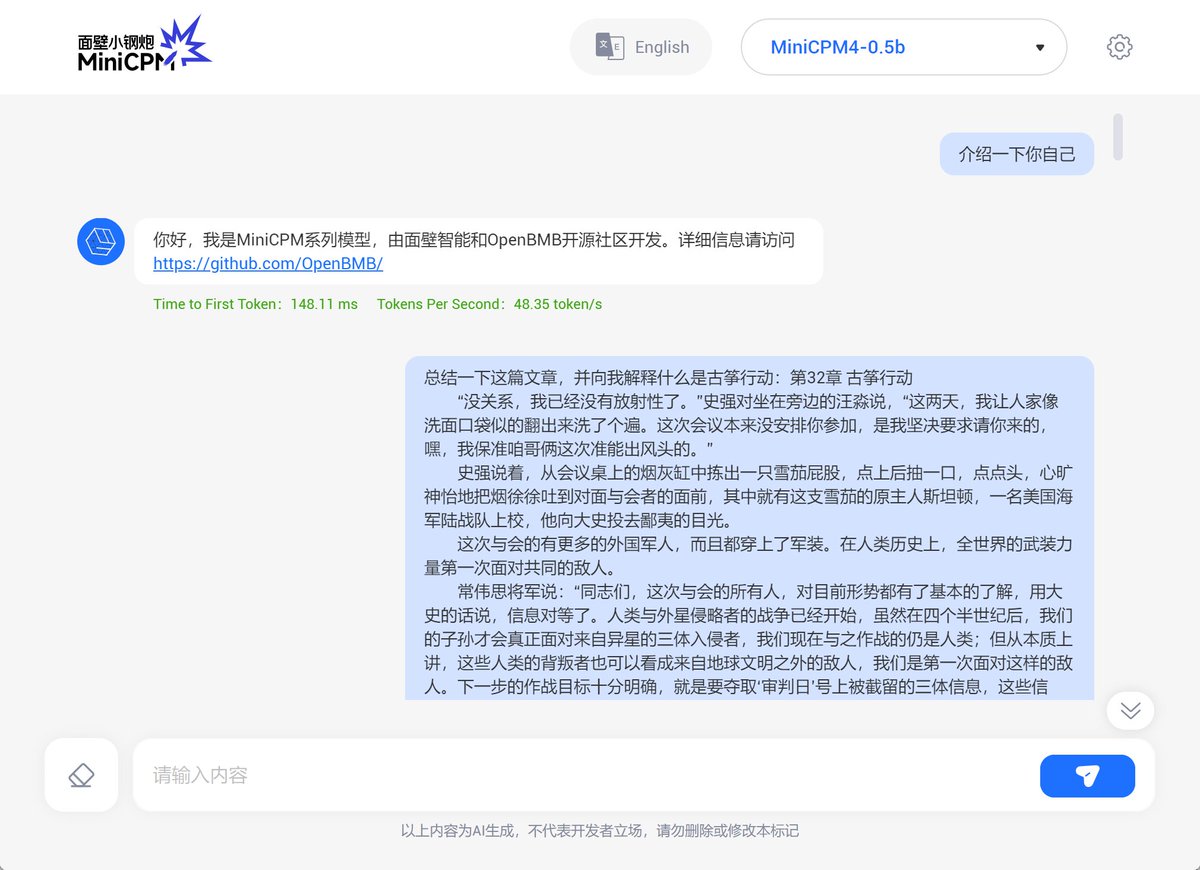
🚀 Big AI models don’t always need powerful servers- MiniCPM Client is now available, and it runs smoothly even on lightweight laptops! ✅ Full support for @intel Core Ultra series ✅ Up to 80 tokens/s with OpenVINO optimization ✅ Low latency, high efficiency, better privacy…

🚀 Introducing CPM.cu 🔥 A lightweight and efficient CUDA inference framework for on-device LLMs — powering the deployment of MiniCPM4! 🎯 Highlights • Integrated Sparse Attention Kernels: Incorporates our InfLLM v2 trainable sparse attention, accelerating…