
Matt Beton
@MattBeton
democratizing ai @exolabs | prev maths @Cambridge_Uni
Training an LLM on 8 M4 Mac Minis Ethernet interconnect between Macs is 100x slower than NVLink so Macs can’t synchronise model gradients every training step. I got DiLoCo running so Macs synchronise once every 1000 training steps using 1000x less communication than DDP

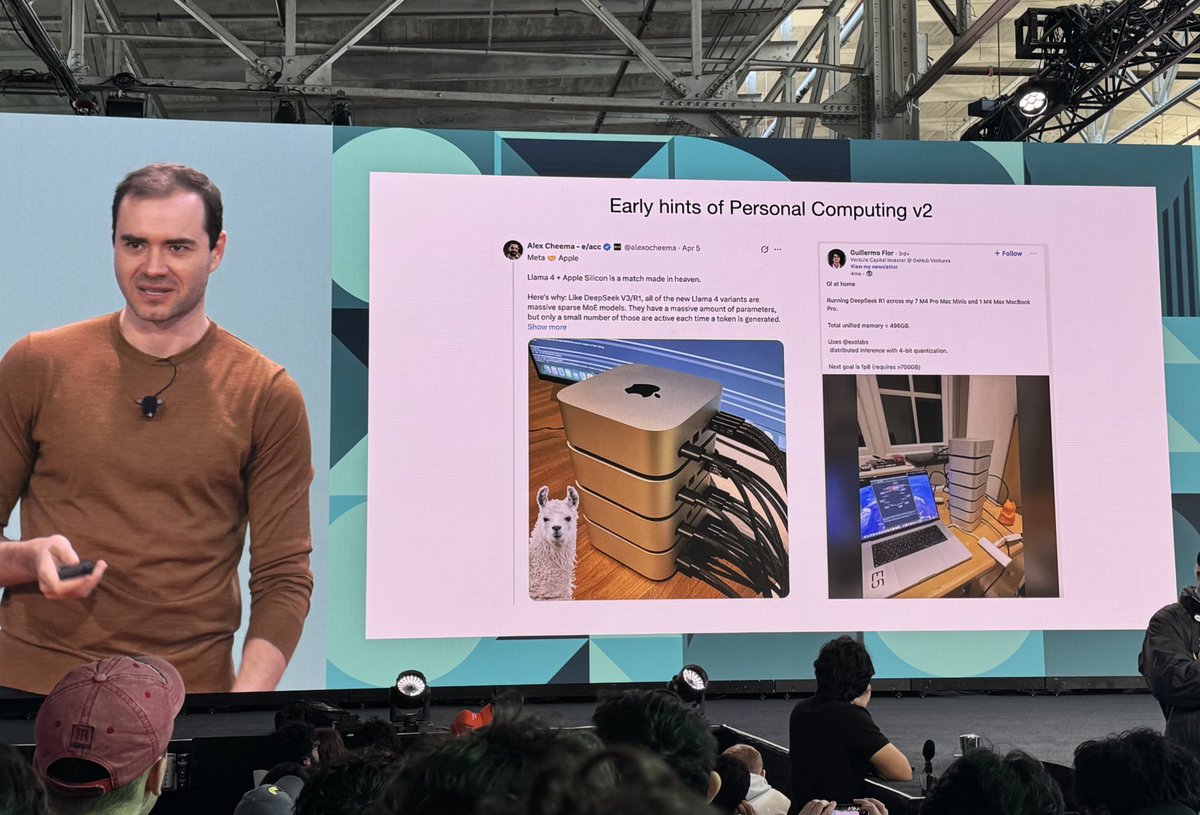
‘The number of Macs that can train together coherently doubles every 2 months’; I'll call this 'Cheema's Law'. And it might sound a joke, but it has been remarkable how much progress we've made on this problem in such a short time. When you're working in a space that is mostly…
We're doubling the number of Apple Silicon macs that can train together coherently every 2 months. Our new KPOP optimizer was designed specifically for the hardware constraints of Apple Silicon and implemented using mlx.distributed.
Kimi K2 was released 15hrs ago and is by far the best open source model, beating DeepSeek R1 in most benchmarks 10 hours later, @sama delays the release of OpenAI’s new open weight model I don’t think this is a coincidence; maybe OpenAI are back to the drawing board to make…
we planned to launch our open-weight model next week. we are delaying it; we need time to run additional safety tests and review high-risk areas. we are not yet sure how long it will take us. while we trust the community will build great things with this model, once weights are…
Why no popular prompt library site yet? 🤔 Prompts take time to write, but are often reusable. This can be commoditized! People often lack ideas for prompts too! A free prompt database would solve this.
clearing out llm-generated slop is the textual equivalent of tidying up the morning after
i never understood 'sf is real-life twitter' until i was there. that place is networking 24/7; everyone and everything important is there. successful british founders told me, 'staying in the uk is a losing battle. you need to give in and move to sf'
Cost to run DeepSeek R1 (fp8) on Apple Silicon: $20,000 Cost to run DeepSeek R1 (fp8) on H100s: $300,000
.@karpathy shouted out my work on @exolabs at @ycombinator AI SUS! “we use LLMs similarly to mainframes in the ‘70s - compute is timeshared by having a slice in the batch dimension. models will compress over time, and with this we’ll be able to run more on-device”
we use LLMs similarly to mainframes in the ‘70s - compute is timeshared by having a slice in the batch dimension models will compress over time, and with this we’ll be able to run more on-device thanks @karpathy for the shout out 🔥
sama alpha leaks on AI-human interfaces: - end goal is ‘computers will melt away’, all interactions will be through the agent - realtime video is a singularity for UX - agents will run in the background; human intervention only when the agent asks for something

i'm in SF for yc startup school! if you're an engineer, builder, researcher - hit me up, would love to chat about what you're working on


it was a pleasure to be asked to give a talk on our paper ‘SPARTA’ at ICLR 2025. distributed training isn’t a fantasy any more; with algorithmic improvements like this, training models over low-bandwidth environments becomes a reality read the paper here: openreview.net/forum?id=stFPf…
Improving the efficiency of distributed training using sparse parameter averaging
are there reasoning models that are better at big-picture thinking/planning, versus lower-level implementation? i’m wondering whether a hybrid strategy of models would be optimal; my workflow at the moment is to plan and theorise with o3, then cursor+claude 4 for implementation