
Long Le
@LongLeRobot
PhD student @Penn. Working on robot learning.
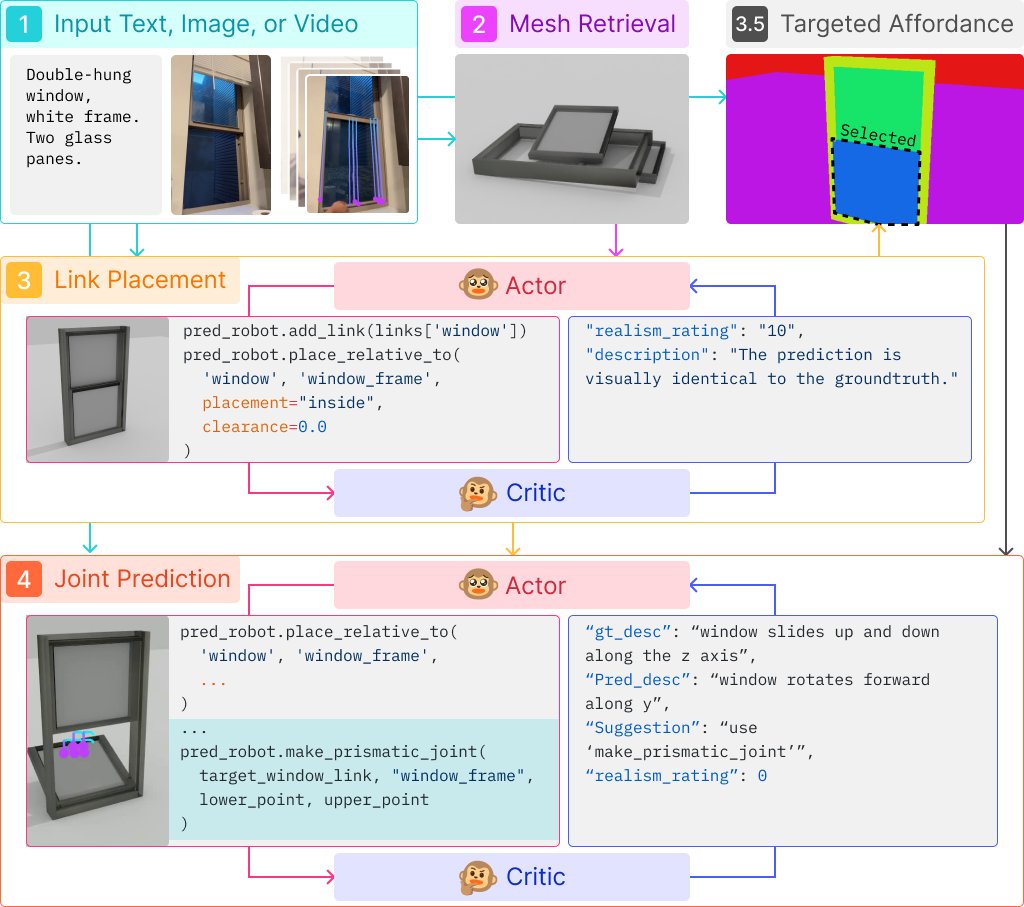
📦 Can frontier AI transform ANY physical object from ANY input modality into a high-quality digital twin that also MOVES? Excited to share our work,Articulate-Anything, exploring how large vision-language models (VLMs) can bridge the gap between the physical and digital…
💡Can robots autonomously design their own tools and figure out how to use them? We present VLMgineer 🛠️, a framework that leverages Vision Language Models with Evolutionary Search to automatically generate and refine physical tool designs alongside corresponding robot action…
Introducing Dynamism v1 (DYNA-1) by @DynaRobotics – the first robot foundation model built for round-the-clock, high-throughput dexterous autonomy. Here is a time-lapse video of our model autonomously folding 850+ napkins in a span of 24 hours with • 99.4% success rate — zero…
most chad poster seen at ICLR. The authors didn’t show up > you guys wouldn’t understand the math anyway

I will be at #ICLR2025 🇸🇬to present our work in leveraging VLMs for articulated object generation! I'm also working on a new method for constructing 3D scenes with physics that I'm very excited about 😤 I'd love to meet new people and chat about robotics and vision! 🤖
🏡Building realistic 3D scenes just got smarter! Introducing our #CVPR2025 work, 🔥FirePlace, a framework that enables Multimodal LLMs to automatically generate realistic and geometrically valid placements for objects into complex 3D scenes. How does it work?🧵👇
🚀 Check out our #CVPR2025 paper BimArt! 👐🔧 We generate 3D bimanual interactions with articulated objects by: ✅ Predicting contact maps from object trajectories ✅ Using an articulation-aware feature representation Project Webpage: vcai.mpi-inf.mpg.de/projects/bimar… @VcaiMpi
During my last research project, I had to interact with VLMs/LLMs a lot so I wrote some wrapper code. Now at: github.com/vlongle/vlmx supporting multiple VLM/LLMs providers, Cursor's style file context, Claude's style artifacts, and in-context multi-modal prompting.

Articulate Anything has just been accepted to @iclr_conf #ICLR2025 ! Looking forward to seeing everyone in Singapore 🇸🇬 🙀❤️!
📦 Can frontier AI transform ANY physical object from ANY input modality into a high-quality digital twin that also MOVES? Excited to share our work,Articulate-Anything, exploring how large vision-language models (VLMs) can bridge the gap between the physical and digital…
Articulate-Anything is now integrated with @Gradio app. Preprocessed dataset is available on @huggingface No more waiting to preprocess the dataset or wrangling with config and command line args. Enter text, drop an image or video in the app, and our system does the rest.
📦 Can frontier AI transform ANY physical object from ANY input modality into a high-quality digital twin that also MOVES? Excited to share our work,Articulate-Anything, exploring how large vision-language models (VLMs) can bridge the gap between the physical and digital…
I love Maniskill. My most recent paper uses Maniskill. Two days ago, as I was trying hopelessly to install IsaacGym, Genesis came out, which looked very impressive. But I’ll most likely stick with Maniskill for the next project: it’s easy-to-install, headless and performant.
Yesterday the hyped Genesis simulator released. But it's up to 10x slower than existing GPU sims, not 10-80x faster or 430,000x faster than realtime since they benchmark mostly static environments blog post with corrected open source benchmarks & details: stoneztao.substack.com/p/the-new-hype…
when you’ve spent 3 hrs installing dependencies locally to run a model and get a CudaOutOfMemory error so you have to install everything on the cluster again
