
Jean de Nyandwi
@Jeande_d
Visiting Researcher @LTIatCMU • Vision 🤍 Language, Multimodal Research • CMU Research blog: http://deeprevision.github.io ML: http://nyandwi.com/machine_learning_complete
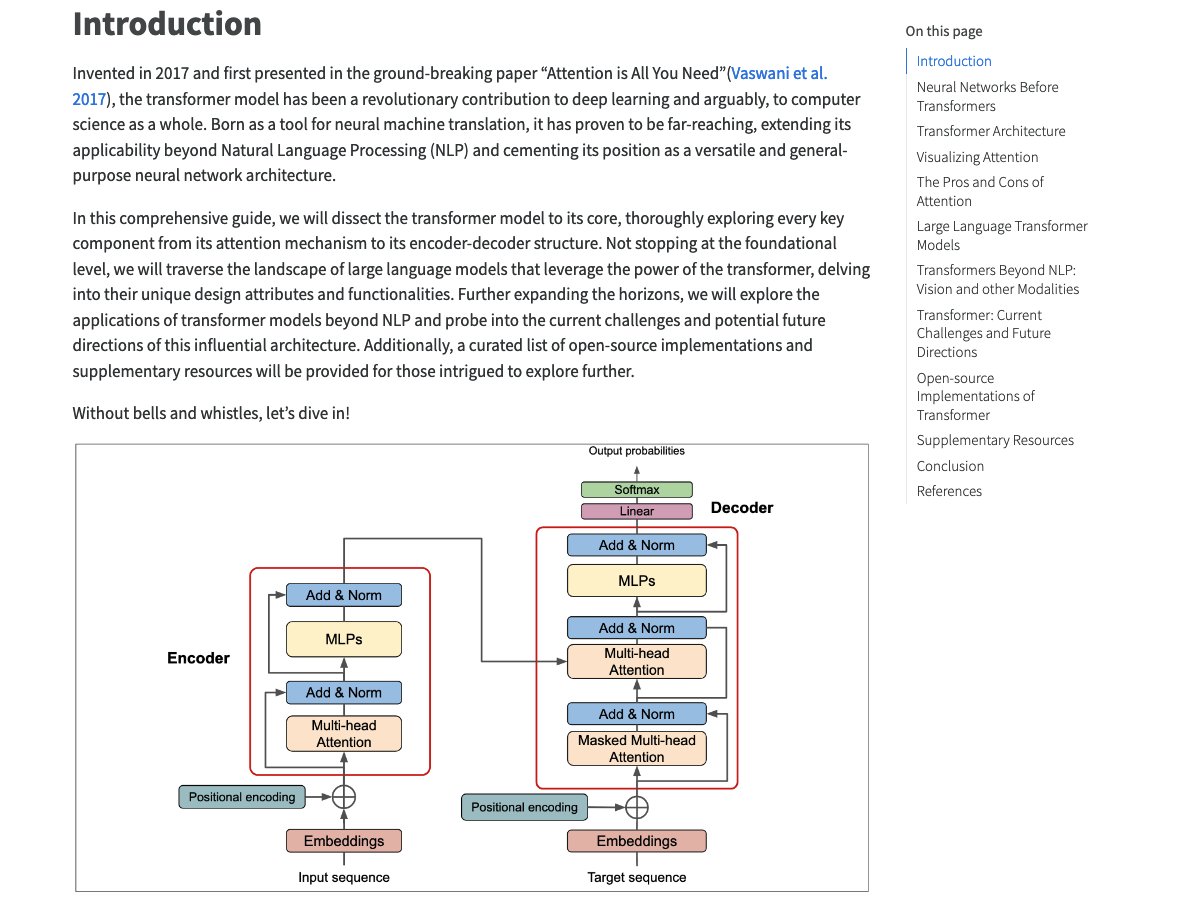
A NEW ARTICLE 🔥🔥 The first article of Deep Learning Revision Research Blog(introduced recently) is out: "The Transformer Blueprint: A Holistic Guide to the Transformer Neural Network Architecture". In the article, we discuss the core mechanics of transformer neural…
People are racing to push math reasoning performance in #LLMs—but have we really asked why? The common assumption is that improving math reasoning should transfer to broader capabilities in other domains. But is that actually true? In our study (arxiv.org/pdf/2507.00432), we…
What will software development look like in 2026? With coding agents rapidly improving, dev roles may look quite different. My current workflow has changed a lot: - Work in github, not IDEs - Agents in parallel - Write English, not code - More code review Thoughts + a video👇
Many people have been asking for an interface to OpenHands that is: 1. easy to install (no docker) 2. can be used in your standard development environment This new CLI checks both of these boxes, and is fun to use!
Introducing the OpenHands CLI, a new coding CLI that: - Has top accuracy (similar to Claude Code) - Is completely open source, MIT licensed - Is model agnostic, use an API or bring your own - Is simple to install and run `pip install openhands-ai` and `openhands` (no Docker!)
New preprint on web agents🚨 Go-Browse: Training Web Agents with Structured Exploration Problem: LLMs lack prior understanding of the websites that web agents will be deployed on. Solution: Go-Browse is an unsupervised method for automatically collecting diverse and realistic…
We've added o4-mini, o3, Claude-4-Sonnet, Gemini-2.5-Flash to our VisualPuzzles leaderboard! 📊 Despite recent advances, even the strongest models still fall short of the lower 5th percentile human reasoning performance (57.5% accuracy). Still a long way to go on multimodal…
Humans can perform complex reasoning without relying on specific domain knowledge, but can multimodal models truly do that as well? Short answer: No. Even the best models perform below the 5th-percentile human on our VisualPuzzles tasks. 🚀 Introducing VisualPuzzles🧩: a new…
How can we vibe code while still maintaining code quality? Over the past year, I've shifted 95% of my development from manually writing code to using coding agents. I wrote this blog on some tricks I learned to work successfully with agents: all-hands.dev/blog/vibe-codi…
📷 Can AI understand camera motion like a cinematographer? Meet CameraBench: a large-scale, expert-annotated dataset for understanding camera motion geometry (e.g., trajectories) and semantics (e.g., scene contexts) in any video – films, games, drone shots, vlogs, etc. Links…
Fresh GPT‑o3 results on our vision‑centric #NaturalBench (NeurIPS’24) benchmark! 🎯 Its new visual chain‑of‑thought—by “zooming in” on details—cracks questions that still stump GPT‑4o. Yet vision reasoning isn’t solved: o3 can still hallucinate even after a full minute of…
🚀 Make Vision Matter in Visual-Question-Answering (VQA)! Introducing NaturalBench, a vision-centric VQA benchmark (NeurIPS'24) that challenges vision-language models with pairs of simple questions about natural imagery. 🌍📸 Here’s what we found after testing 53 models…
Humans can perform complex reasoning without relying on specific domain knowledge, but can multimodal models truly do that as well? Short answer: No. Even the best models perform below the 5th-percentile human on our VisualPuzzles tasks. 🚀 Introducing VisualPuzzles🧩: a new…
A big two days of agents starting tomorrow at CMU (and then two days of agent hackathon after that!) Registration is still open so if you're in or around Pittsburgh come one come all: cmu-agent-workshop.github.io We also plan to livestream for participants who can't make it in person
People at Artificial Analysis are doing good job on comparing models across important axes: intelligence, speed, and price. And for all modalities and tasks: language, speech, video, image, code. Benchmarks are not perfect but there is no other way to know a model is better than…
OpenAI’s GPT-4o Image Generation debuts with an ELO score in equal first-place in the Artificial Analysis Image Arena, outperforming Recraft V3, FLUX 1.1 [pro] and Gemini 2.0 Flash @OpenAI last week launched GPT-4o Image Generation, upgrading ChatGPT’s built-in image generation…
Today's a big day! Months of work went into both of these releases, so we hope people enjoy them. OpenHands is now a great coding agent that you can run entirely locally (w/ OpenHands LM), and a great coding agent that you can run anywhere (w/ OpenHands Cloud).
Today, we're excited to make two big announcements! - OpenHands LM: The strongest 32B coding agent model, resolving 37.4% of issues on SWE-bench Verified 📈 - OpenHands Cloud: SOTA open-source coding agents from your computer, phone, github, with $50 in free credits 🙌☁️