
Hu Xu (@ICML25)
@Hu_Hsu
FAIR, Data Research, end-end data model and training, MetaCLIP (scaling CLIP from scratch), DINOv2, Llama
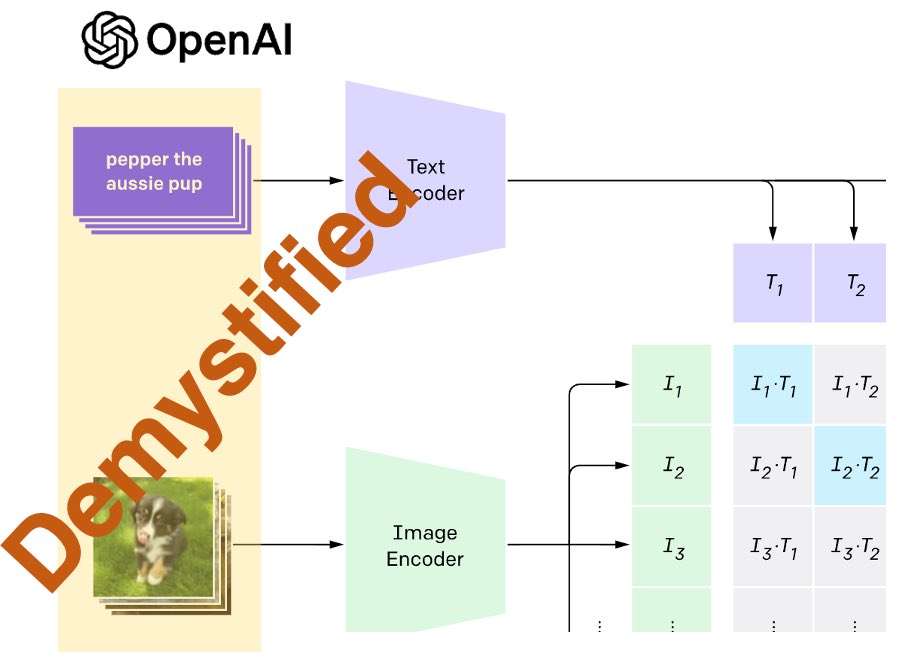
🎉 MetaCLIP accepted as #ICLR2024 spotlight. Big thxs/cong. to @sainingxie @ellenxtan0 @berniebear_1220 @RussellHowes1 @sharmavasu55 @ShangwenLi1 @gargighosh @LukeZettlemoyer @cfeichtenhofer and @_akhaliq post. Code github.com/facebookresear… w/ ViT-G(IN 82.1)/demo/metadata builder.
Excited Meta CLIP 1.2 is in this release during #NeurIPS2024, now we have a synthetic engine re-aligning hard alt-texts as hard and dense captions.
It's been a big year for AI, and today I'm excited to share nine new open source releases from Meta FAIR to wrap up the year — all part of our mission to achieve advanced machine intelligence (AMI). So proud of this team and looking forward to 2025! ai.meta.com/blog/meta-fair…
It's been a big year for AI, and today I'm excited to share nine new open source releases from Meta FAIR to wrap up the year — all part of our mission to achieve advanced machine intelligence (AMI). So proud of this team and looking forward to 2025! ai.meta.com/blog/meta-fair…
Thanks for the invited talk and happy to share our industrial insights on “scaling data alignment” from Meta CLIP (its wide adoption and what’s next) in the DataWorld workshop #ICML2025 . happy to chat offline about data research.
If you are attending #ICML2025, check out our DataWorld workshop on Sat July 19. We have updated the website with more info on speakers & accepted papers! dataworldicml2025.github.io Also happy to chat offline about all things ✨ data ✨
Heading to #ICML2025 (first time). Excited to meet need friends and old friends and chat about foundational data research and co-design with training (MetaCLIP), SelfCite arxiv.org/abs/2502.09604 with @YungSungChuang and LongVU arxiv.org/abs/2410.17434 with @xiaoqian_shen .
A new start of FAIR and excited to be part of it.
Rob Fergus is the new head of Meta-FAIR! FAIR is refocusing on Advanced Machine Intelligence: what others would call human-level AI or AGI. linkedin.com/posts/rob-ferg…
Congrats @rob_fergus ! Big win for FAIR
1/ Excited to share that I’m taking on the role of leading Fundamental AI Research (FAIR) at Meta. Huge thanks to Joelle for everything. Look forward to working closely again with Yann & team.
Great to see MetaCLIP algorithm (arxiv.org/abs/2309.16671) desaturate SSL training distribution as SSL 2.0. What’s next in SSL or pre-training? From our data research perspective, it’s likely about how to automatically desaturate a training distribution.
New paper from FAIR+NYU: Q: Is language supervision required to learn effective visual representations for multimodal tasks? A: No. ⬇️⬇️⬇️
excited to see the next level of generalization: from human’s (as one type of agent) experience to agent’s experience. TBH, experience is a better name of ‘data’, and next x prediction is learning from past experience.
David Silver really hits it out of the park in this podcast. The paper "Welcome to the Era of Experience" is here: goo.gle/3EiRKIH.
get information dense image training distribution is the key to decide what to keep or compress in representation; it’s probably time to rethinking what is supervision, no matter if it’s directly in loss or clear annotation process.
New paper from FAIR+NYU: Q: Is language supervision required to learn effective visual representations for multimodal tasks? A: No. ⬇️⬇️⬇️
congrats the release with many surprises features.
Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality. Llama 4 Scout • 17B-active-parameter model…
It’s also true if we break down one project: it’s extremely hard to execute step 1 to n-1 or define what is step 1; it’s easy to execute step n (by another party).
it is (relatively) easy to copy something that you know works. it is extremely hard to do something new, risky, and difficult when you don't know if it will work. individual researchers rightly get a lot of glory for that when they do it! it's the coolest thing in the world.
it is (relatively) easy to copy something that you know works. it is extremely hard to do something new, risky, and difficult when you don't know if it will work. individual researchers rightly get a lot of glory for that when they do it! it's the coolest thing in the world.
The slide from @ilyasut at #neurips2024 seems mean, the so-called scaling on data is never scalable in theory, because the process of creating human/agent supervision is not scalable. Excited to see his future research to break this barrier.

This slide reminds me to build definitions first: pre-training means scaling on both model and data. One Internet means the data growth is not scalable(quality data that made blind scaling works even grow at sub constant rate). Then what to scale if not pre-training data.
Brilliant talk by @ilyasut, but he's wrong on one point. We are NOT running out of data. We are running out human-written text. We have more videos than we know what to do with. We just haven't solved pre-training in vision. Just go out and sense the world. Data is easy.
Due to urgent family issue, will miss #EMNLP2024 but have amazing @ellenxtan0 present Altogether at 4pm on Tuesday, Session 04, join if you are interested in the next generation of synthetic data and image captioning.
(1/5) 🎉[New Paper] Altogether: Image Captioning via Re-aligning Alt-text arxiv.org/abs/2410.17251 is accepted by #EMNLP2024 : we re-align existing alt-texts as captions for images instead of captioning images from scratch (e.g. MS-COCO captioning).