
Surge AI
@HelloSurgeAI
Human data for AGI. Our mission: to raise AGI with the richness of human intelligence — curious, witty, imaginative, and full of unexpected brilliance.
Small, focused teams can achieve incredible things — very proud of what we’ve built! theinformation.com/articles/littl…

Olympics? Forget it. There's a more exciting race going on 😎 Congrats to all our friends at Google!

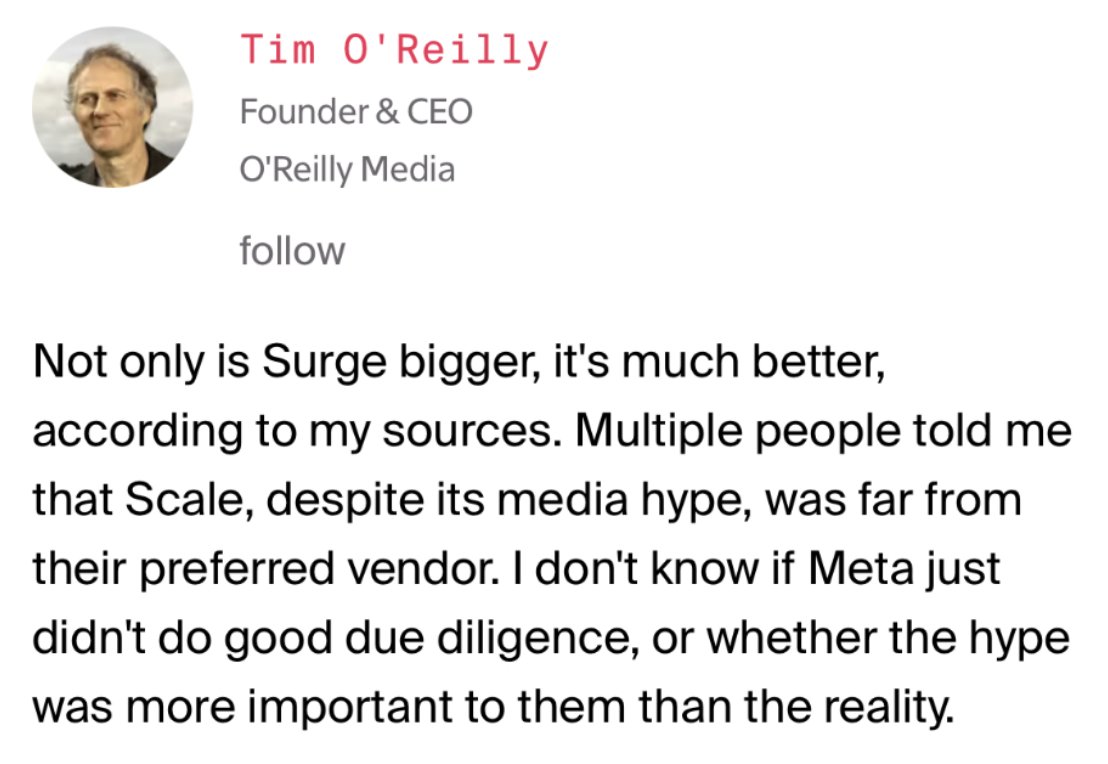
How do you know Gemini is seriously next-level? Because as Demis says, it's “the most preferred chatbot in blind evaluations with third-party raters” 😎 🪅 Congrats to all our Google friends! 🪅
Bard is now called Gemini; and Gemini Advanced with Ultra 1.0 has launched! It was the most preferred chatbot in blind evaluations with third-party raters. And it’s now available on mobile on Android and iOS. Have fun trying it out!
Big congrats to the Bard and Gemini teams! 🥳 blog.google/products/bard/…

🎉Congrats on the massive achievement by Meta AI on Llama 2! We are proud to accelerate and power the next generation of AI and LLMs and excited to see the wider adoption of Llama and the deep innovation happening in the ecosystem. Llama is being used for all sorts of…
In addition to all of the new product announcements at #MetaConnect2023, you heard about some of the research and AI models that helps bring these new features to life. Here's a look at some of the work you should know about + the research papers where you can learn more ⬇️
Making LLMs reliable is a tough task. But this is where a lot of the LLM research and development work is focused. Let's take a look at how LLMs are made reliable: At Surge AI, we work with the top AI companies to improve LLM reliability. This effort is essential to enable…

The most powerful LLMs in the world are trained on Surge AI’s RLHF. Some of these models include code LLMs which are going to be huge for progress in AI! Let’s look at some of the recent developments in code LLMs: Foundational Code LLMs - Research indicates that foundational…
Human Evaluation in LLMs One of the more challenging aspects of LLM research is evaluation. Here are some of our observations based on past and ongoing research: At Surge AI, we provide human evaluation for finetuning and RLHF and for both closed and open-source LLMs. Human…
What is SFT data and what role does it play in state-of-the-art LLMs? Supervised finetuning (SFT) in the context of RLHF deals with further tuning an initial language model using demonstration data. At Surge AI, we provide SFT data for top LLM teams to finetune their LLMs. Here…

RLHF enables some of the most powerful LLMs today. One of the key components in RLHF LLMs is human preference data which makes it possible to align LLMs with human preferences. Here are some key insights: The reward model fundamentally enables tuning an RLHF LLM to align with…

RLHF continues to accelerate innovation in both closed and open-source LLMs. What exactly is accelerating this innovation? Here are 4 general patterns we are observing: - In the RLHF framework, collecting high-quality SFT data is key to achieving high-quality results and…
Red teaming is a critical part of ensuring LLMs are safe, but it’s not often discussed. At Surge AI, we red team LLMs for many of the major AI labs, including Anthropic and Microsoft. We care deeply about this problem as it aligns with our core mission to build safe and useful…

New research shows that language models exhibit inverse scaling! You heard that right! LMs may show worse task performance with increased scale. This is caused by several factors according to empirical evidence on datasets collected via a public contest. This is a big deal!…
