
Haihao Shen
@HaihaoShen
Creator of #intel Neural Compressor and AutoRound; HF Optimum-Intel Maintainer; OPEA & COIA TSC; Opinions are my own
🎯More low-bit models are coming, including 2 & 4 bits gguf, 4 bit autoround, gptq, ... huggingface.co/Intel/Qwen3-23… huggingface.co/Intel/Qwen3-23… huggingface.co/Intel/Qwen3-23… #intel #autoround #qwen #huggingface

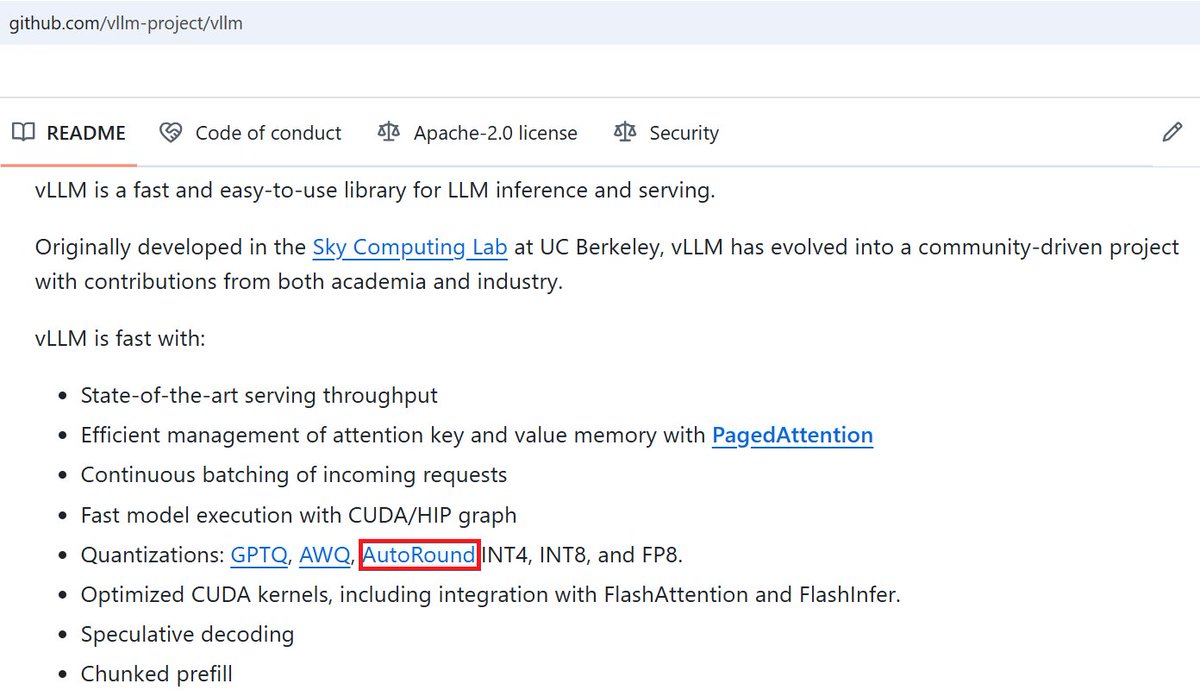
🎯AutoRound is now helping vLLM deliver more accurate and faster LLM inference. Check it out and give a try!
🥳INT4 model for updated Qwen3-235B-A22B: huggingface.co/Intel/Qwen3-23… vLLM MoE seems not working well; yet HF transformers can run pretty well.

Solid DeepSeek-R1 performance on Xeon from @kalomaze 🍻
wtf, Intel got 550 tokens/sec prefill and 15 tokens/s output using dual socket xeon 6980P (without a GPU) for int8 deepseek
Congrats Mingfei and the team! Thanks to the excellent collaborations between @lmsysorg and Intel! #intel #sglang #xeon
🚀Summer Fest Day 3: Cost-Effective MoE Inference on CPU from Intel PyTorch team Deploying 671B DeepSeek R1 with zero GPUs? SGLang now supports high-performance CPU-only inference on Intel Xeon 6—enabling billion-scale MoE models like DeepSeek to run on commodity CPU servers.…
🎯Sharing the best-quality Qwen3 INT4 models powered by Intel Neural Compressor and AutoRound algorithm👇 huggingface.co/Intel/Qwen3-30… huggingface.co/Intel/Qwen3-14… huggingface.co/Intel/Qwen3-8B… Hope these models would help and you would get the accuracy benefits in your deployment.

💡Intel Neural Compressor v3.4 is released, supporting more quantization recipes, e.g., W4A8 (FP8). In the past weeks, we've contributed the algorithm AutoRound to HF Transformers and vLLM, and now we are making the contribution to SGLang. Stay tuned.😀 🎯github.com/intel/neural-c…
🔥A nice intro and demo video for AutoRound - check it out and give a try!
AutoRound is the easy button for language model quantization. It supports a variety of word lengths, device types, and quantization formats. Learn how to get started: youtube.com/watch?v=LszyOP…
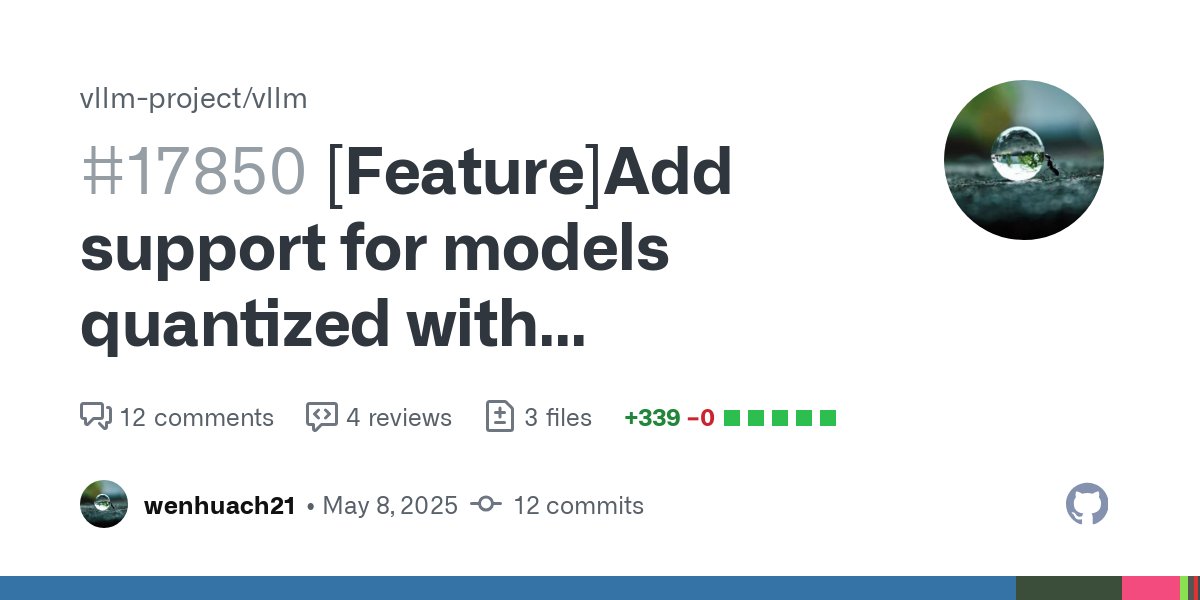
🎯AutoRound is now part of @vllm_project with more VLMs, higher accuracy, more formats (AWQ/GPTQ/GGUF). Congrats @wenhuach & thanks @mgoin_ 💡We highly recommend using AutoRound to generate AWQ models in the future, as AutoAWQ is no longer maintained. github.com/vllm-project/v…
👉Qwen3 support on Intel platforms across data center, edge, and client: intel.com/content/www/us…

AutoRound is now in 🤗 Transformers! Intel’s PTQ tool brings accurate INT2–INT8 quantization to LLMs & VLMs — fast, flexible, and hardware-friendly (CPU, CUDA, Intel GPU). > Mixed-bit, GPTQ/AWQ/GGUF export, 72B in minutes > Models on Hugging Face (OPEA, etc.) 🔗 Benchmarks +…
🎯Thrilled to share our blog on "AutoRound", an advanced quantization approach for LLMs 👀Blog: huggingface.co/blog/autoround Thanks to @wenhuach @kding & Intel teams and @_marcsun & HF friends!

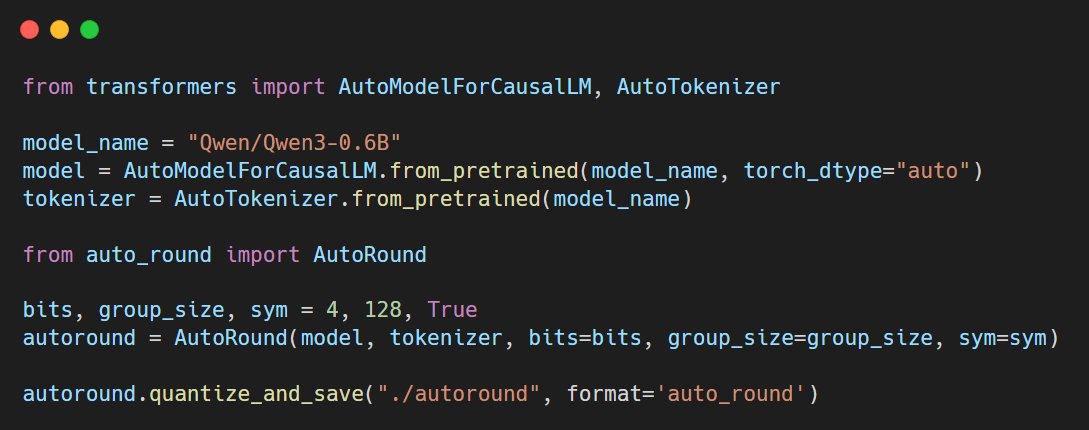
🔥AutoRound supports day0 Qwen3 launch! Check out the sample code from github.com/intel/auto-rou…. Now you can get the best INT4/3 Qwen3 models using AutoRound.
Congrats @JustinLin610 and Qwen team! Really excited to have #intel Neural Compressor (github.com/intel/neural-c…) be part of SW partners for day0 launch! Cheers 🍻
Introducing Qwen3! We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general…
🔥AutoRound, a leading low-precision library for LLMs/LVMs developed by Intel, officially landed on @huggingface transformers. Congrats to Wenhua, Weiwei, Heng! Thanks to Ilyas, Marc, Mohamed from HF team! github.com/huggingface/tr… #intel @ClementDelangue @julien_c
👇Strongly recommending watching the video created by @delock and I believe you would like it as I do.🥳 youtube.com/shorts/kNCMf2C…
📢Sharing a printed "gold" necklace, designed by @delock. Loved it 😍 with my Github ID. 🎯Released 3D modelling file (not LLM modelling!!!) which can be further customized with your Github ID. Enjoy! makerworld.com/en/models/1209…

🪜Step by step to generate INT4 DeepSeek-R1 model using Intel's AutoRound tool, while delivering higher accuracy than FP8 or any other open-sourced INT4 model (see #evaluate section in model card) 🤖Tool: github.com/intel/auto-rou… 🎯Model: huggingface.co/OPEA/DeepSeek-…
