Delta Lake
@DeltaLakeOSS
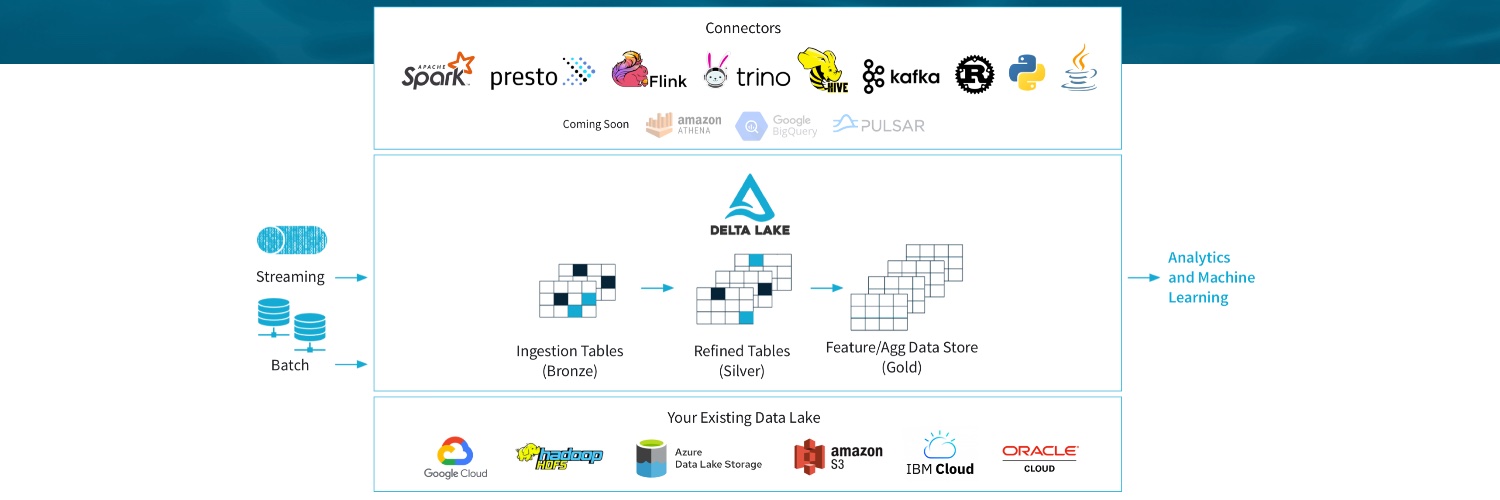
Delta Lake is an open-source storage framework that enables building a Lakehouse architecture for Spark, Flink, Trino, Hive, Scala, Java, Rust, Python, & more!
Curious about how Delta Lake structures its tables and achieves both scalability and reliability? In our recent webinar, Scott Haines breaks down the building blocks of a #DeltaLake table: 🔹 Partitioned storage — boosts performance and query efficiency 🔹 Parquet files —…
🎥 Now Available: Delta-Kernel-RS — Unparalleled Interoperability Across Query Engines At #DataAISummit, Robert Pack and Zach Schuermann (@Databricks) introduced Delta-Kernel-RS — a new #Rust implementation of the Delta Lake protocol designed for unparalleled interoperability…

In this walkthrough, ChanChan Mao with @daftengine shows how #Daft and #DeltaLake can work together by merging complex datasets (image metadata, annotations, categories) and writing them natively to Delta Lake, complete with partitioning and Delta log tracking—no #JVM, no #Spark…
In this clip, Ion Koutsouris (Rustacean & Delta Maintainer) explains how @lakeFS garbage collection policy integrates with #DeltaLake to manage unreferenced files and automate cleanups. By leveraging Spark jobs, lakeFS ensures your Delta Lake storage remains lean and organized.…
“We cut our streaming ingestion costs over 90% by adopting kafka-delta-ingest, which means we can invest those savings in really interesting large language model products or innovative data processes.” — R. Tyler Croy, Principal Engineer at @Scribd & Maintainer of delta-rs 💬…
🚀 From Delta Lake to downstream ML pipelines — without Spark? In this clip, Daniel Beach shares a real production use case where he used Polars inside an Apache Airflow worker to read from a @unitycatalog_io–backed #DeltaLake table, filter job-specific records, and dynamically…
"With over three petabytes of processed data and more than 1,200 active users, our Lakehouse platform powered by Delta Lake is at the core of how we drive insights at scale." - Satya Mandavilli, Solutions Architect at @SPGlobal Learn how S&P Global puts Delta Lake at the center…
In this blog, R. Tyler Croy (Buoyant Data) shares how re-architecting his data pipeline with Rust and the oxbow architecture for Delta Lake writes reduced resource usage to just 1% of the previous setup: a massive win for both cost and sustainability! 🌱🌐 Academic research and…

In this clip, @YoussefMrini explains how deletion vectors in #DeltaLake help you avoid rewriting #Parquet files for every update or delete. Instead, a bitmap marks which rows are deleted, so files are only rewritten when necessary. This approach minimizes repeated file rewrites…
Ever wondered how @lakeFS integrates with Delta Lake? In this short clip, Ion Koutsouris walks through the process. ✅ With lakeFS and Delta Lake, your data changes are managed safely—even when multiple people are working at the same time. Conflicts are handled automatically, so…
Join the conversation on Delta Lake GitHub Discussions! 💬 Have questions, ideas, or updates about Delta Lake? Curious about community decisions? 🤔 GitHub Discussions is the place for open conversations, Q&A, and community-driven collaboration around Delta Lake. ✅ Ask and…

Thank you all for your love and support after last week’s funding announcement, it means everything to us. This week, let’s highlight ways you can interact with and use Daft. Starting off with @DeltaLakeOSS, Daft internally uses the deltalake Python package to fetch metadata…
Announcing: Row Tracking Write Support in Delta Kernel Java 🚀 The latest release of Delta Kernel Java introduces support for writing to row tracking-enabled tables! ✅ Track individual rows: Accurately identify which rows have been inserted, updated, or deleted in your tables.…

𝗗𝗲𝗹𝘁𝗮 𝗟𝗮𝗸𝗲 𝟰.𝟬 𝗶𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗲𝘀 𝗗𝗲𝗹𝘁𝗮 𝗖𝗼𝗻𝗻𝗲𝗰𝘁 — bringing Delta Lake support to Spark Connect for Apache Spark! 🚀 With Delta Connect, you can run all #DeltaLake operations remotely from lightweight clients, thanks to a decoupled client-server…

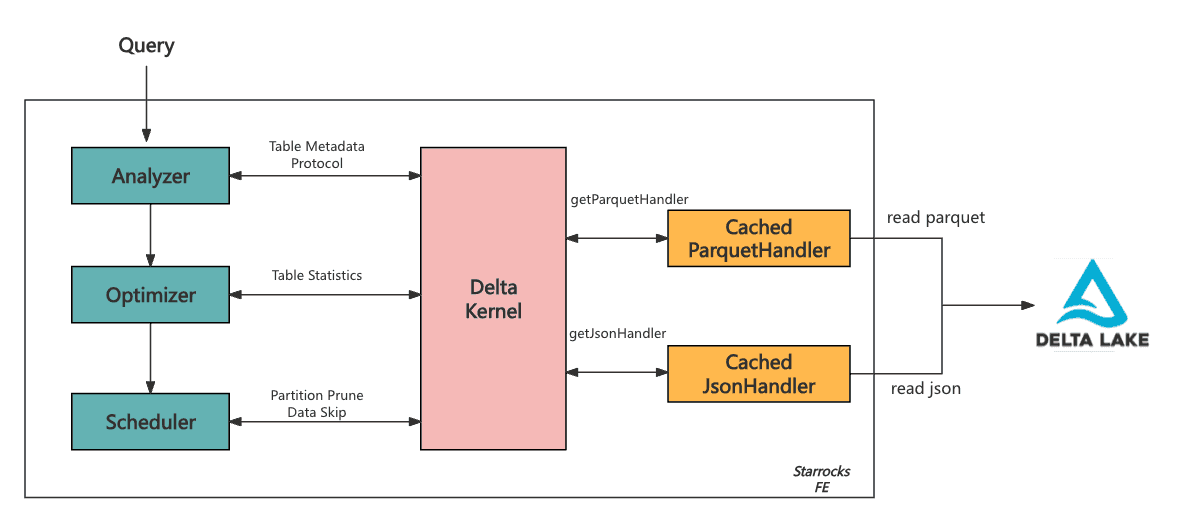
⚡ Supercharging Customer-Facing Analytics with Delta Kernel + @StarRocksLabs Delta Lake’s Delta Kernel offers a robust set of Engine APIs to make data access faster and more efficient. StarRocks taps into these APIs to power smart caching techniques that: 🔹 Eliminate redundant…
DNB achieved a 90% cost reduction by adopting a serverless pipeline using Delta Lake, @DuckDB, @ApacheArrow, kafka-delta-ingest (github.com/delta-io/kafka…), and Azure Container App Jobs. 🙌⭐ This new approach leverages Delta’s transaction identifiers for efficient, stateful…
