DeepSpeed
@DeepSpeedAI
Official account for DeepSpeed, a library that enables unprecedented scale and speed for deep learning training + inference. 日本語 : @DeepSpeedAI_JP
Improved DeepNVMe: Affordable I/O Scaling for AI - Faster I/O with PCIe Gen5 - 20x faster model checkpointing - Low-budget SGLang inference via NVMe offloading - Pinned memory for CPU-only workloads - Zero-copy tensor type casting Blog: tinyurl.com/yanbrjy9



1/4⚡️nanoton now supports DoMiNo with intra-layer communication overlapping, achieving 60% communication hiding for tensor parallelism (TP) in both the forward and backward passes while maintaining the same training loss.
Kudos to Xinyu for giving an excellent presentation of DeepSpeed Universal Checkpointing (UCP) paper at USENIX ATC 2015.
📢 Yesterday at USENIX ATC 2025, Xinyu Lian from UIUC SSAIL Lab presented our paper on Universal Checkpointing (UCP). UCP is a new distributed checkpointing system designed for today's large-scale DNN training, where models often use complex forms of parallelism, including data,…
My first project at @Snowflake AI Research is complete! I present to you Arctic Long Sequence Training (ALST) Paper: arxiv.org/abs/2506.13996 Blog: snowflake.com/en/engineering… ALST is a set of modular, open-source techniques that enable training on sequences up to 15 million…
PyTorch Foundation has expanded into an umbrella foundation. @vllm_project and @DeepSpeedAI have been accepted as hosted projects, advancing community-driven AI across the full lifecycle. Supporting quotes provided by the following members: @AMD, @Arm, @AWS, @Google, @Huawei,…
Come hear all the exciting DeepSpeed updates at the upcoming PyTorch Day France 2025 DeepSpeed – Efficient Training Scalability for Deep Learning Models - sched.co/21nyy @sched
Introducing 🚀DeepCompile🚀: compiler-based distributed training optimizations. - Automatic parallelization & profile-guided optimizations - Enable ZeRO1, ZeRO3, Offloading, etc. via compiler passes - 1.2X-7X speedups over manual ZeRO1/ZeRO3/Offloading tinyurl.com/8cys28xk

AutoTP + ZeRO Training for HF Models - Enhance HF post-training with larger models, batches, & contexts - 4x faster LLAMA3 fine-tuning with TP=2 vs TP=1 - No code changes needed Blog: tinyurl.com/5n8nfs2w

🚀 Excited to introduce DeepSpeed, a deep learning optimization library from @Microsoft! It simplifies distributed training and inference, making AI scaling more efficient and cost-effective. Learn more 👉 hubs.la/Q0351DJC0 #DeepSpeed #AI #OpenSource #LFAIData
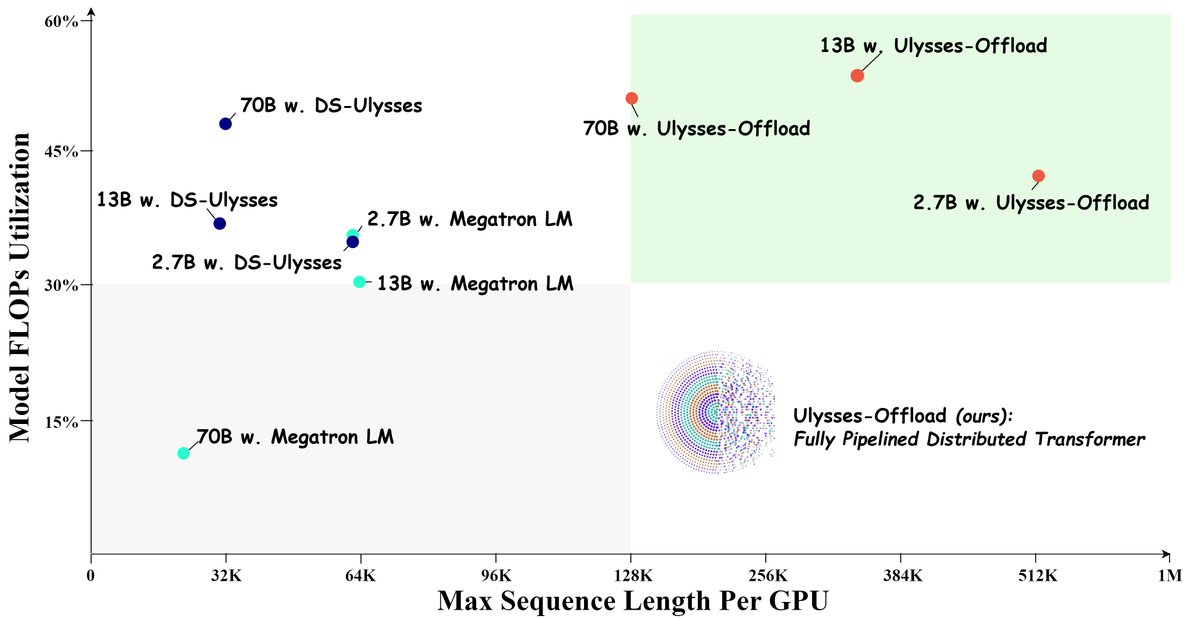
🚀Introducing Ulysses-Offload🚀 - Unlock the power of long context LLM training and finetuning with our latest system optimizations - Train LLaMA3-8B on 2M tokens context using 4xA100-80GB - Achieve over 55% MFU Blog: shorturl.at/Spx6Y Tutorial: shorturl.at/bAWu5
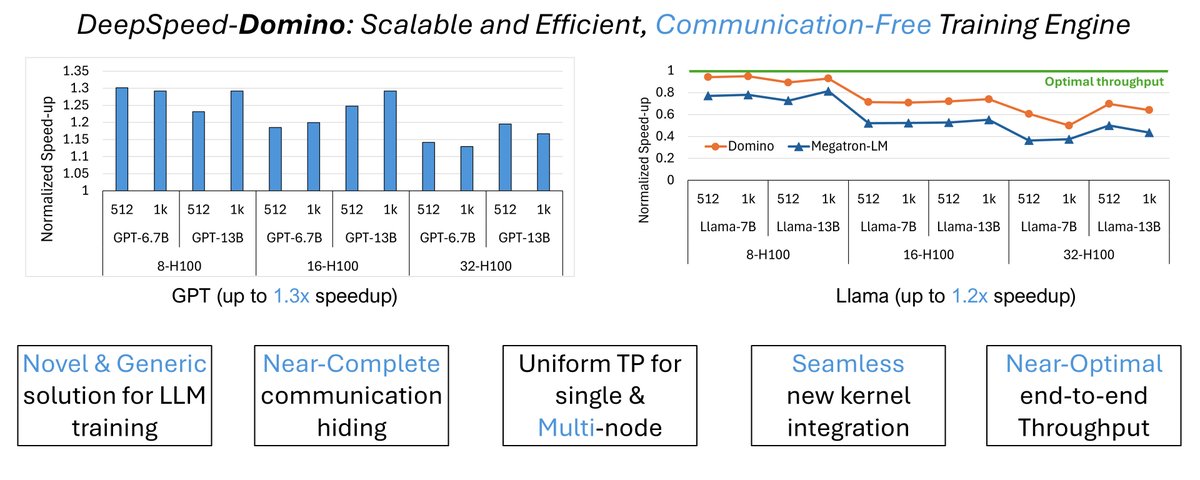
Introducing Domino: a novel zero-cost communication tensor parallelism (TP) training engine for both single node and multi-node settings. - Near-complete communication hiding - Novel multi-node scalable TP solution Blog: github.com/microsoft/Deep…
Great to see the amazing DeepSpeed optimizations from @Guanhua_Wang_, Heyang Qin, @toh_tana, @QuentinAnthon15, and @samadejacobs presented by @ammar_awan at MUG '24.
Dr. Ammar Ahmad Awan from Microsoft DeepSpeed giving a presentation at MUG '24 over Trillion-parameter LLMs and optimization with MVAPICH. @OSUengineering @Microsoft @OhTechCo @mvapich @MSFTDeepSpeed @MSFTDeepSpeedJP #MUG24 #MPI #AI #LLM #DeepSpeed
Announcing that DeepSpeed now runs natively on Windows. This exciting combination unlocks DeepSpeed optimizations to Windows users and empowers more people and organizations with AI innovations. - HF Inference & Finetuning - LoRA - CPU Offload Blog: shorturl.at/a7TF8

💡Check out Comet’s latest integration with DeepSpeed, a deep learning optimization library! 🤝With the @MSFTDeepSpeed + @Cometml integration automatically start logging training metrics generated by DeepSpeed. Try the quick-start Colab to get started: colab.research.google.com/github/comet-m…
Introducing DeepNVMe, a suite of optimizations for fast and efficient I/O operations in DL applications. - POSIX-style APIs - Direct HBM/NVMe xfers via NVIDIA GDS - Cheap Inference scaling via NVMe-Offload Blog: shorturl.at/l7Oue @Azure @NVIDIADC #FMS24 #GPUDirect

Introducing Universal Checkpointing for boosting training efficiency. - Change parallelism (PP, SP, TP, ZeRO-DP) or GPU count mid-stream - Improve resilience by scaling down to healthy nodes💪 - Increase throughput by scaling up to elastic nodes🚀 Blog: rb.gy/aup3pn

#DeepSpeed joins forces with @Sydney_Uni to unveil an exciting tech #FP6. Just supply your FP16 models, and we deliver: 🚀 1.5x performance boost for #LLMs serving on #GPUs 🚀 Innovative (4+2)-bit system design 🚀 Quality-preserving quantization link: github.com/microsoft/Deep…

So you've had your fun with @karpathy 's mingpt. Now its time to scale : introducing min-max-gpt: really small codebase that scales with help of @MSFTDeepSpeed . No huggingface accelerate, transformer. Just deepspeed + torch: maximum hackability github.com/cloneofsimo/mi…
Hear, hear, AMD MI300Xs have started to emerge much sooner than expected. Here is a 2-part benchmarks report on performing BLOOM-176B inference using @MSFTDeepSpeed optimized for AMD MI300X. 1. evp.cloud/post/diving-de… 2. evp.cloud/post/diving-de… This was published in response…
🪁 Today we're releasing the code to train your very own Zephyr models! We've worked hard to make this as accessible as possible, so you can run: 🏋️♂️ Full fine-tuning with @MSFTDeepSpeed ZeRO-3 on A100s 🐭 LoRA or QLoRA fine-tuning on consumer GPUs Code: github.com/huggingface/al…