Chase Brower
@ChaseBrowe32432
software dev, working on AI stuff
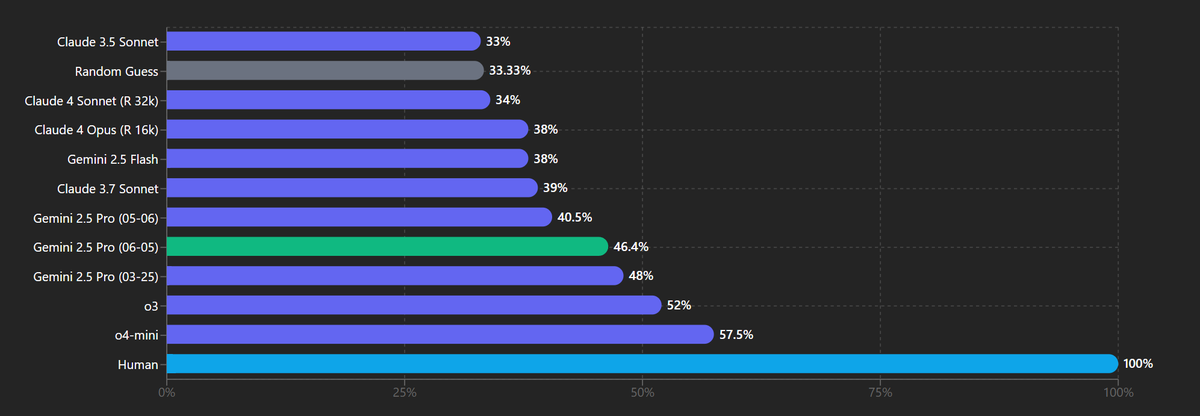
Gemini 2.5 Pro 06-05 scored 46.4% on my visual physics reasoning test (VPCT) avg@5 Pretty solid
Y'know, I've now seen this exact pattern from almost every single one of the voices in this field I've respected most, each for their own respective pet problem. "How do we know LLMs are a poor research direction with no future? Because they can't do thing x!" >LLMs succeed in…

METR previously estimated that the time horizon of AI agents on software tasks is doubling every 7 months. We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
When will AI systems be able to carry out long projects independently? In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
Introducing FrontierMath Tier 4: a benchmark of extremely challenging research-level math problems, designed to test the limits of AI’s reasoning capabilities.

Running SWE-bench evals is very slow and difficult. To solve this, we created a registry of optimized Docker images that let us run SWE-bench Verified in just one hour on a single 32-core machine. Today, we are open-sourcing these images— anyone can `docker pull` them.
We have detected copyrighted material in your brainweights. You are not allowed to see and remember copyrighted material per 17 U.S.C. § 101. Please proceed to the nearest authorized memory transplant office.
sama 7T investment was a prophecy
The bottlenecks to >10% GDP growth are weaker than expected, and existing $500B investments in Stargate may be tiny relative to optimal AI investment In this week’s Gradient Update, @APotlogea and @ansonwhho explain how their work on the economics of AI brought them to this view
RL for RL reward is inversely proportional to the step count needed to reach a given performance through RL across several tasks task-RLed model branches are discarded