
Bertrand Charpentier
@Bertrand_Charp
Founder, President & Chief Scientist @PrunaAI | Prev. @Twitter research, Ph.D. in ML @TU_Muenchen @bertrand-sharp.bsky.social @[email protected]
Happy to announce NatPN at #ICLR2022 (Spotlight) ! - It predicts uncertainty for many supervised tasks like classification & regression. - It guarantees high uncertainty for far OOD. - It only needs one forward pass at testing time. - It does not need OOD data for training.
🧑🏫 AI Efficiency Fundamentals - Week 4: Quantization We see quantization everywhere, but do you know the difference between static and dynamic quantization? Even if you do, these slides are great for you. At Pruna, we want to educate about efficient AI, so our lead researcher…
🔥 Deploy custom AI models with Pruna optimization speed + @lightningai LitServe serving engine! Lightning-Fast AI Deployments! What makes this awesome: • ⚡️ FastAPI-powered serving • 🎯 Built-in batching • ⚙️ Define and serve any model (vision, audio, text) • 🚀 Easy…
From Wan video to Wan Image: We built the fastest endpoint for generating 2K images! - Accessible on @replicate : lnkd.in/eqsBR2Kx - Check details, examples, and benchmarks in our blog: lnkd.in/eXcAbqjM - Use Pruna AI to compress more AI models:…
📷 Introducing Wan Image – the fastest endpoint for generating beautiful 2K images! From Wan Video, we built Wan Image which generates stunning 2K images in just 3.4 seconds on a single H100 📷 Try it on @replicate: replicate.com/prunaai/wan-im… Read our blog for details, examples,…
🚀 𝗣𝗿𝘂𝗻𝗮 𝘅 @𝗴𝗼𝗸𝗼𝘆𝗲𝗯 𝗣𝗮𝗿𝘁𝗻𝗲𝗿𝘀𝗵𝗶𝗽 𝗨𝗽𝗱𝗮𝘁𝗲! 🔥 Early adopters are reporting great results from our lightning-fast inference platform: Performance Breakthrough: • ⚡️ Much faster models • 💰 Cost reduction • 🎯 Minimal quality degradation Let’s talk…
Super happy to welcome @sdiazlor in the team!
Say hello to Sara Han, the newest member of our Developer Advocacy team! With a laptop and his puppy on her lap, she'll help build connections between Pruna and developers to make models faster, cheaper, smaller and greener. Her time at @argilla_io and @huggingface, combined…
How to make AI endpoints having less CO2 emissions? 🌱 One solution is to use endpoints with compressed models. This is particularly important when endpoints run at scale.
🌱 Compressing a single AI model endpoint can save 2t CO2e per year! In comparison, a single EU person consumes ~10t CO2 per year. Last week, our compressed Flux-Schnell endpoint on @replicate has run 𝟮𝗠 𝘁𝗶𝗺𝗲𝘀 𝗼𝗻 𝗛𝟭𝟬𝟬 𝗼𝘃𝗲𝗿 𝟮 𝘄𝗲𝗲𝗸𝘀. For each run, the model…
🧑🏫 AI Efficiency Fundamentals - Week 1: Large Language Architectures Do you know the difference between Autoregressive, Diffusion, and State-Space LLMs? Even if you do, these slides are great for you. At Pruna, we want to educate about efficient AI, so our lead researcher and…
We made Flux-Kontext-dev from @bfl_ml x5 faster in <4h and deployed in on @replicate. Hope that you will enjoy! We put details in our blog: pruna.ai/blog/flux-kont… :)
Open-weights @bfl_ml FLUX.1 Kontext [dev] is now open-source! It allows to perform image-to-image generation with state-of-the-art quality :) However, it takes ~14.4 seconds for each generation on one H100. When we learned about this, we were in our offsite to chill together…
🔥 Community: ”Image editing is too damn slow!” Don’t worry, we accepted the challenge of making HiDream-e1 faster and it is now at 8,7s on an H100! :) ☕︎ Take a coffee, sit back and relax, as the model has been run over 20,000 times on @replicate already! 👇 Model URL in the…
With @PrunaAI x @replicate, video generation with Wan 2.1 is now fast and accessible in one click!
This week @Alibaba_Wan published the new VACE videos models? We make them already x1.3 to x2.5 faster! 🚀 Once again, you can directly enjoy the speed on the @Replicate endpoints: - Wan2.1 VACE 14B: replicate.com/prunaai/vace-1… - Wan2.1 VACE 1.3B: replicate.com/prunaai/vace-1…
𝗛𝗼𝘄 𝘁𝗼 𝗹𝗲𝗮𝗿𝗻 𝗮𝗯𝗼𝘂𝘁 𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁 𝗔𝗜? Happy to announce the Awesome AI Efficiency repo that gathers a 𝗰𝘂𝗿𝗮𝘁𝗲𝗱 𝗹𝗶𝘀𝘁 𝗼𝗳 𝟭𝟬𝟬+ 𝗺𝗮𝘁𝗲𝗿𝗶𝗮𝗹𝘀 to understand the challenges and solutions in making AI faster, smaller, cheaper, greener. 🚀 It is…
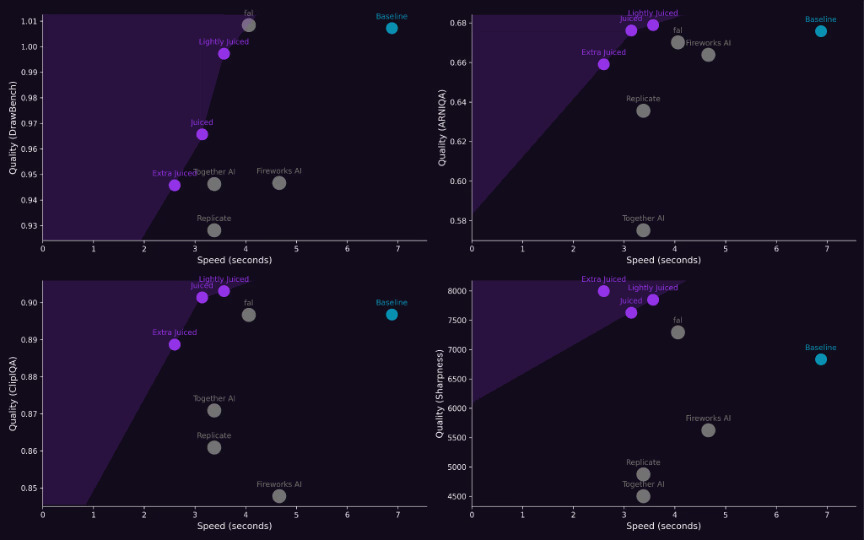
💥Flux-juiced end point pushes the limits of image generation performance for both efficiency and quality!💥 - Try Flux-Juiced on Replicate: lnkd.in/eBYCnhwg - Read the full benchmarking blog on Hugging Face : lnkd.in/epRWuidn
𝗦𝗮𝘆 𝗵𝗲𝘆 𝘁𝗼 𝗗𝗮𝘃𝗶𝗱 𝗕𝗲𝗿𝗲𝗻𝘀𝘁𝗲𝗶𝗻 (x.com/davidberenstei) — 𝗣𝗿𝘂𝗻𝗮’𝘀 𝗻𝗲𝘄 𝗗𝗲𝘃𝗥𝗲𝗹 𝗮𝗹𝗰𝗵𝗲𝗺𝗶𝘀𝘁! 🧪🤖 From Hugging Face & Argilla to homemade pasta 🍝, David’s all about precision, flavor & flow! Now he’s cooking with us at Pruna to make models…
In a single day, we compressed and deployed the SOTA HiDream for optimized efficiency. Try it with your favorite prompts on @replicate :)
Recent HiDream models from @vivago_ai rank #1 for image generation? We make them x1.3 to x2.5 faster! 🚀 Directly enjoy the speed on the @Replicate endpoints: • HiDream fast: replicate.com/prunaai/hidrea… • HiDream dev: replicate.com/prunaai/hidrea… • HiDream full:…
💦 Everything’s fine… until it isn’t. 🔥 Generative AI runs on code and concrete, metals, heat, and vapor. Let’s talk about the real infrastructure behind your prompts. 🏗⚙️🔥💨 🗓 April 15, 5PM UTC 🔗 linkedin.com/events/7309948…
We open-sourced the pruna package! 🌍🚀 - It supports various compression methods such as pruning, quantization, distillation, and caching that can be combined! - It enables easy evaluation of efficiency and quality of compressed models! Now, developers around the world can…
Pruna AI open sources its AI model optimization framework tcrn.ch/41Gx2Kp