
kinnif
@0xkinnif
techno-optimist | @fisher8cap | @partyhatDAO
the more you sweat in peace, the less you bleed in war thank you Kajino for this amazing piece ❤️

The first ever Shuffle lottery jackpot has been hit 🍾 $2,509,021 USDC going to the lucky winner!
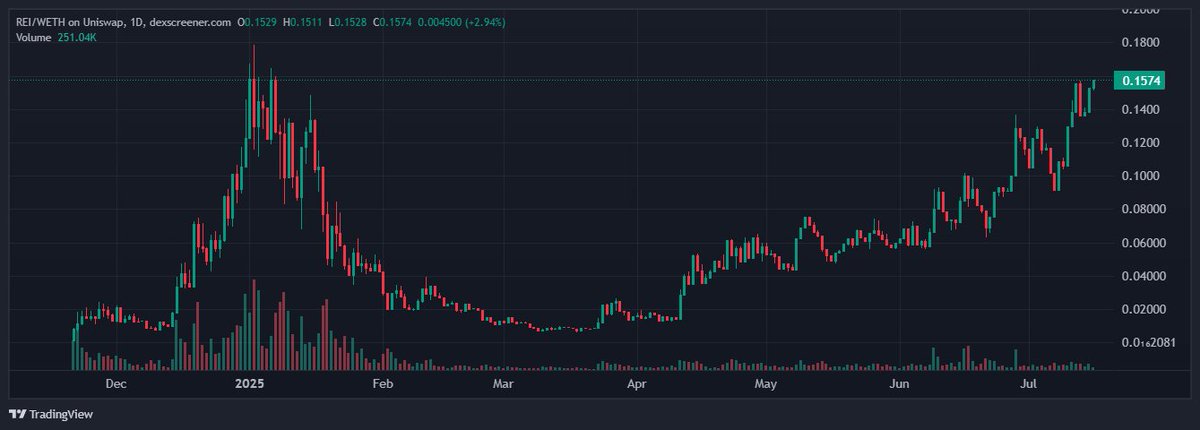
$REI x.com/ReiNetwork0x/s… With HYPE's regain of momentum and interest to play within the HL eco (s2 ad, hyperunit launch etc) decent selection as one of the majors in HL eco Been holding a spot bag for sometime and been adding on 0.618 fib tests (from local low to high)
i have been training my unit for analysing pro dota 2 matches with extraordinary results. despite having no gameplay experience (and with limited micro skills), it has been predicting matchup outcomes with a 75% confidence score modelled by the unit itself and produced a win…
Excited to share @Neutrl_Labs has chosen USDe as the core asset within their basis strategies Neutrl is bringing institutional-grade, market-neutral strategies onchain by combining OTC deal flow with basis trading via USDe to create accessible, crypto-native yield Learn more…
x.com/i/article/1945…

there will be apps there will be ecosystems there will be speculation there will be AGI
i have been training my unit for analysing pro dota 2 matches with extraordinary results. despite having no gameplay experience (and with limited micro skills), it has been predicting matchup outcomes with a 75% confidence score modelled by the unit itself and produced a win…
Walking Users Through The New Paradigm - Training at Inference Time : mirror.xyz/0x9Aa5228e5072….
who needs a coach when you have $rei
Congrats to @nmss_gg for qualifying for The International 2025! Competitive gaming environments are valuable to test the ability of systems to process new information because it requires constant adaptation to evolving strategies. Traditional RLHF optimizes responses via…
Congrats to @nmss_gg for qualifying for The International 2025! Competitive gaming environments are valuable to test the ability of systems to process new information because it requires constant adaptation to evolving strategies. Traditional RLHF optimizes responses via…
i have been training my unit for analysing pro dota 2 matches with extraordinary results. despite having no gameplay experience (and with limited micro skills), it has been predicting matchup outcomes with a 75% confidence score modelled by the unit itself and produced a win…