
Toshii
@0xToshii
unpaid intern, eng arc
released the (n)th challenge (20+) for my smart contract CTF: Mr Steal Yo Crypto all challenges are based on real world exploits and are well suited for devs exploring #solidity/#security primer & hints: degenjungle.substack.com/p/mr-steal-yo-… challenges: mrstealyocrypto.xyz

checked the diff-apply methods used per model(s) for a subset of our internal harder diff-apply data (non-overlapping examples) my guess prior to checking this was that block anchor search was used way more, but evidently was wrong
checked the prevalence of diff-apply methods per model for the "hard" benchmark. kinda interesting altho its a pretty small sample diff-apply rails are important fr
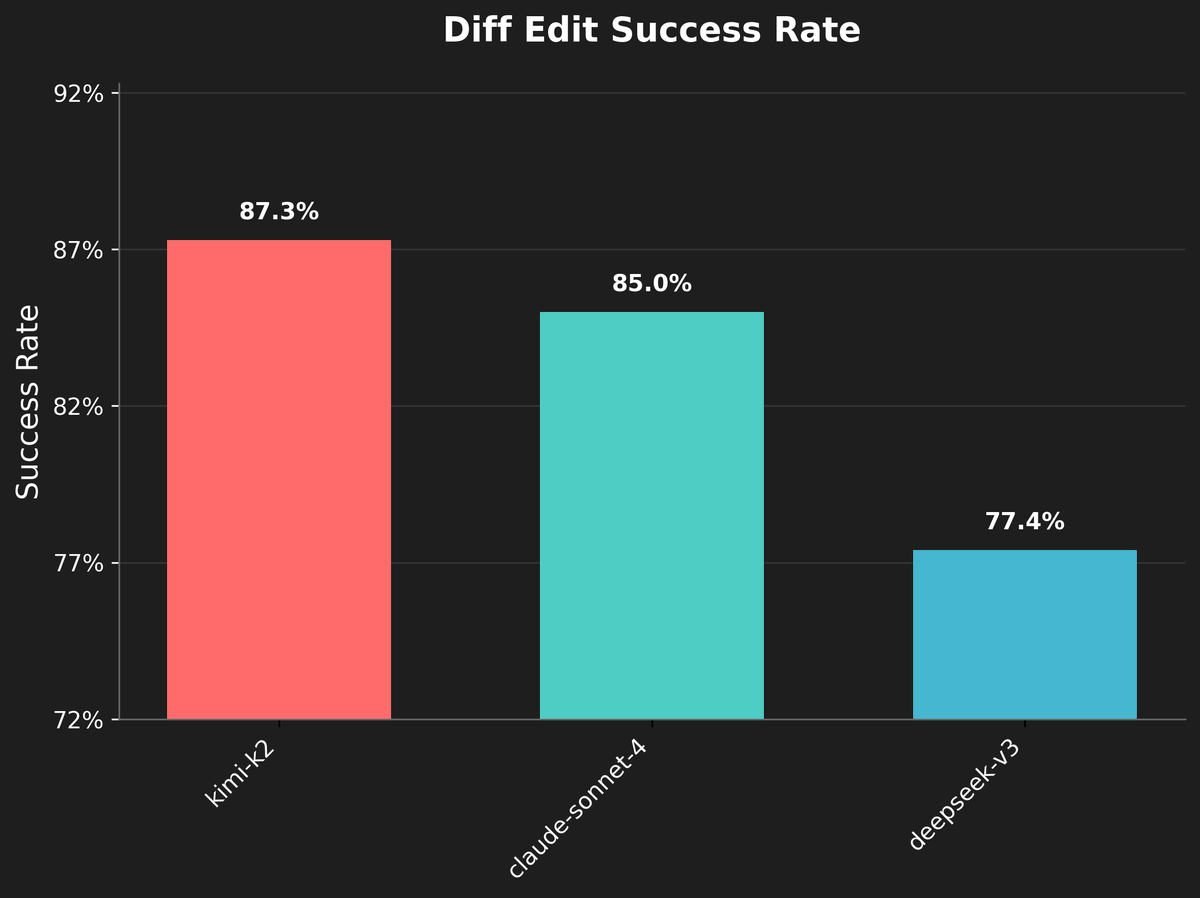
updated data for the cline weekly diff edit success rate metrics now that qwen3 coder has been out for a bit notice anything different?
cline diff edit success rate per llm(s) over the last wk an interesting follow up question is how different models might be used more or less often on tasks of varying difficulty, and if/how that skews this data
been hearing things
Less than two weeks Kimi K2's release, @Alibaba_Qwen's new Qwen3-Coder surpasses it with half the size and double the context window. Despite a significant initial lead, open source models are catching up to closed source and seem to be reaching escape velocity.
v excited to see where we go from here with os models
I'd like to point out that for the real world tasks (not benchmarks), Kimi K2 outperforms Gemini. This is telemetry across all @cline users, showing diff edit failure rate. Notice how Kimi has about a 6% failure rate, which is significantly better than Gemini's ~ 10% error…
end of any possible US DeepSeek/Kimi moment? Not sure who else has the appetite and scale Llama2 was the first ~os model series i was genuinely surprised & impressed by, and Llama3 was a banger. Honestly felt the Meta LLMs could be the standard

alright Kimi K2 might be cooking ran this through our small Cline diff edit eval set. Again, this just measures success rate for valid diff edit attempts. The percentage of valid / total attempts: Kimi K2 (25%), DeepSeek V3 (35.8%), Sonnet 4 (45.3%)

hunting for bugs off platform was pretty fun but rug rate was too high to sustain motivation
this cursor stuff just reminded me that i submitted a high sev bug to zharta (steal all yield from vault) a year ago and they still haven't paid me they had offered some amount of a token which still doesn't exist lmao
this cursor stuff just reminded me that i submitted a high sev bug to zharta (steal all yield from vault) a year ago and they still haven't paid me they had offered some amount of a token which still doesn't exist lmao
checked the prevalence of diff-apply methods per model for the "hard" benchmark. kinda interesting altho its a pretty small sample diff-apply rails are important fr
quick thread on how the @cline diff-apply algo works kinda interesting logic since it supports streamed inputs & has rails for boosting valid applies when the llm output is malformed vv